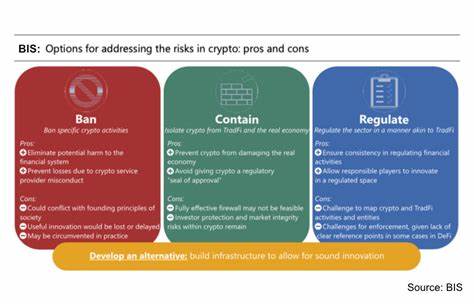
在现代软件开发中,数据的高效序列化和跨语言传递变得尤为重要。随着微服务架构和多语言混合开发的普及,传统的序列化框架面临着性能瓶颈和兼容性挑战。Apache Fory作为一个开源的跨语言高性能序列化框架,通过其最新发布的0.11.0版本展现了强大的创新能力和技术突破,为开发者提供了更加灵活且高效的数据序列化解决方案。Apache Fory的前身是Apache Fury,在此次重大版本升级中完成了品牌重命名,同时伴随极具价值的功能与性能提升。此次版本的发布标志着Apache Fory在跨语言数据序列化领域迈入了一个新的纪元,特别是在Java、Python、C++、Dart以及Go等多种编程语言间实现了无缝数据共享,并且针对复杂数据结构和动态变化的需求提供了更优表现。核心亮点之一是Dart语言序列化的支持,填补了此前Apache Fory在移动端及前端开发应用中的空白,使得数据处理更加统一和高效。
新增的基于块的映射序列化协议极大优化了Java和Python之间的性能与互操作性。通过分块处理,框架在处理大型映射数据时,显著降低内存占用并加快序列化和反序列化速度,特别适合实时数据传输和大数据分析场景。Apache Fory进一步统一了Java和跨语言对象序列化标准,支持枚举、时间类型、多维数组等复杂类型的兼容处理,增强了跨语言的数据一致性和有效验证能力。此外,新版本对Python性能优化颇多,包括对字典、元组及列表序列化性能提升,并借助C-API接口降低操作开销。这种针对关键数据结构的加速不仅提升了Python应用的响应速度,也保证了与Java等语言间的互通效率。Row格式的演进是另一个技术亮点,新增对Optional类型、记录(Records)、嵌套Bean以及接口合成的支持,使得序列化对象模型更加丰富且灵活。
开发者可以轻松处理更多样化的业务对象,同时保持数据传输的简洁和高效。项目代码库、Maven的groupId、jar包名称以及文档中都完成了从Apache Fury向Apache Fory的全面迁移,这一变更虽涉及多个组件,但更好地统一了项目品牌形象和用户认知。除此之外,新版本加强了对Java端的JIT支持,改进了缓冲区大小限制的配置选项,持续提升序列化过程的性能。C++部分则引入了基于SIMD指令的字符串编码优化,提升了UTF-8及UTF-16编码的处理速度,为高性能系统提供了有力保障。对于跨语言数据的无缝集成,Apache Fory的最新xlang类型系统实现了更为严谨和高效的规范,通过该规范,Java、Python、Go以及其他语言能够以一致的方式处理集合、映射及自定义类型,极大减少了数据转换的复杂度。除功能突破外,性能方面的提升亦非常显著。
Python基准测试脚本经过增强,支持多平台包括Windows和macOS的编译环境。同时内存管理和缓冲区优化减少了序列化过程的资源消耗,使得在大规模数据场景下的稳定性和效率得到保障。开发团队还针对protobuf消息及字节串添加了专门的序列化支持,为面向网络传输的应用提供了更符合业界标准的组件。Java端新增了多样化的校验、配置及错误处理机制,包括保证序列化过程中缓存一致性、防止非法类型注册等,显著提升了框架在实际生产环境中的鲁棒性。Apache Fory对新兴编程语言如Kotlin和Dart的持续支持,更显示了其适应现代开发潮流的决心和敏锐度。Continuous Integration(CI)流程的完善保障了版本更新的稳定性和高质量交付。
此次版本发布还伴随着大量Bug修复,改进了日志记录、并发处理及跨平台兼容性等关键问题,从而为用户提供了更为流畅和可靠的使用体验。综合来看,Apache Fory 0.11.0版本以其丰富的功能更新和卓越的性能优化,为跨语言分布式系统的数据交换树立了新标杆。其强大的扩展性和灵活适配能力,使其不仅适用于传统企业级应用,也为人工智能、大数据分析及物联网等新兴领域提供了坚实基础。对于寻求高效、统一序列化框架的开发团队,Apache Fory无疑是一个不可忽视的利器。随着该项目的不断发展,可以预见Apache Fory将在大规模数据交互和多语言生态系统中发挥越来越核心的作用,推动软件架构向更高效、更智能的方向迈进。