随着软件系统规模的不断扩大和复杂性的提升,开发团队在维护和更新过程中面临的挑战日益严峻。软件问题定位,即根据自然语言描述的缺陷报告、功能请求等,精准找出相关代码位置,成为软件开发中极其关键却耗时耗力的环节。传统技术在应对这类任务时效率有限,而最近兴起的基于大型语言模型(LLM)的方案虽然表现突出,却存在运行成本高、响应速度慢等瓶颈。面向这些问题,新兴的SweRank框架应运而生,以其创新的代码排序机制和大规模数据支持,成为提升软件问题定位能力的重要工具。 软件问题定位的核心使命是将开发者提交的自然语言问题描述,准确匹配到项目中可能关联的代码文件、类或者函数。由于输入的查询包含大量冗长且具备一定故障特征的自然语言,传统的查询到代码(query-to-code)检索模型往往难以捕捉其内在语义和上下文信息,导致定位结果不理想。
与此同时,近几年基于Agent模型和闭源LLM的多步骤推理方法逐渐兴起,如Claude-3.5等,它们依托强大的语言理解能力,能够完成复杂推断任务。然而,这类方法受限于模型闭源性和推理耗时,难以在大规模工业场景中灵活应用。 SweRank提出了一套高效的检索及重排序(retrieve-and-rerank)框架,专门针对软件问题定位的独特需求进行设计。此框架分两个阶段,首先通过轻量级检索器快速筛选候选代码区域,随后利用精细化的重排序模型提升结果的准确度。这种方法平衡了效率与精准,为开发者节省了大量定位时间,同时保证推荐的代码位置与问题描述高度契合。 为了打破数据瓶颈,SweRank团队构建了SweLoc数据集,囊括了大量源自公共GitHub仓库的实际软件项目中的问题描述及其对应的代码改动。
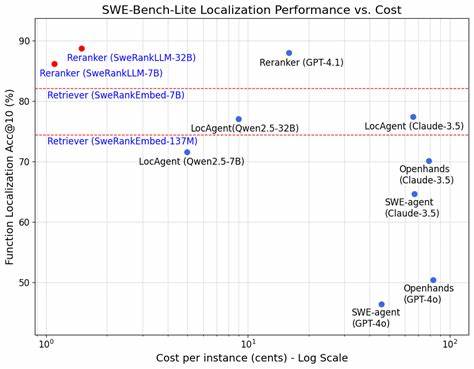
该数据集大规模、多样化,涵盖不同编程语言和项目类型,极大提升了模型训练的泛化能力和实际应用价值。在此基础上,SweRank框架在多个主流测试平台如SWE-Bench-Lite和LocBench上取得了卓越表现,超越了现有的传统排名模型和昂贵的闭源LLM代理系统,彰显了技术的先进性和实用性。 除了核心框架外,SweLoc数据集的问世本身也成为软件工程领域的宝贵资源。开发者和研究人员可以借助这一数据集改进现有检索模型,提高问题与代码匹配的准确率,推动自然语言处理与软件工程的深度融合。SweRank的成功展示了结合大规模真实数据与高效排序技术的巨大潜力,为以后的智能软件维护工具研发树立了标杆。 当前软件行业正处于向智能化转型的关键阶段。
自动化的问题定位不仅能显著缩短问题处理周期,还能降低开发人员因定位失误带来的成本。SweRank正是这一趋势的产物,其在问题描述理解与代码检索效率上的平衡,为复杂软件项目的维护提供了便捷高效的技术支持。未来,随着SweLoc的持续扩展和技术的不断优化,SweRank及类似框架有望进一步提升智能定位能力,助力更多企业实现自动化质量保障。 值得特别关注的是,SweRank的设计理念不仅限于单一模型架构,更强调系统的整体效率与开放性。相比依赖封闭的云端大语言模型,SweRank侧重于可扩展、低成本的本地部署解决方案,为企业提供更灵活的应用选择。此外,框架的模块化设计便于与现有开发工具链集成,形成闭环的自动化开发环境,极大提升团队协作与项目管理的效率。
总结来看,SweRank代表了软件问题定位技术的重大突破。它通过创新的代码排序算法和丰富的数据资源,解决了传统模型面对冗长且复杂问题描述时的性能瓶颈。其在提升定位准确率和节省开发时间方面表现卓越,符合软件行业追求高效、智能的趋势。随着技术的不断演进,SweRank及其衍生产品将引领软件维护的新潮流,推动整个行业迈向更加智能化、自动化的未来。