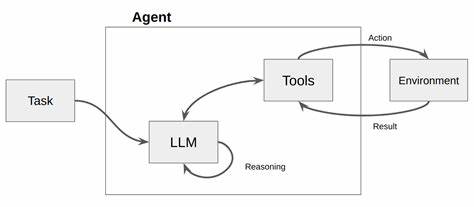
随着人工智能特别是大语言模型(LLM)的快速发展,越来越多的企业开始依赖这些智能系统来完成复杂的任务调用,如调用企业内部API来实现自动化办公、数据查询和业务管理。然而,实际应用中这些大语言模型面对工具调用时仍存在明显短板,尤其在多种相似工具或功能模块间辨析用户意图时容易出现误调用或遗漏重要参数,导致业务流程受阻。近期提出的一项创新技术——基于消歧义(disambiguation-centric)微调方法,为解决这一难题带来了新的突破。该方法通过构建一个名为DiaFORGE的对话生成与评估框架,实现了对企业级工具调用的大语言模型进行指向性极强的训练,显著提升了模型在近似工具选择和参数补全方面的表现。本文将详细解读该技术的核心理念、实现机制及其在构建更真实、低风险的工具调用智能代理中的实际价值。大型语言模型在拥抱企业复杂场景的过程中,面临的最大挑战之一便是如何有效在多种相近或功能重叠的API工具中明确识别用户意图。
传统依赖单纯的上下文预测或模板匹配的方法难以满足这一需求,尤其在用户提出的问题表述模糊或参数不足时,模型往往容易陷入错误工具调用。例如,在多个几乎功能相同但针对不同细分业务的API工具间选择,普通模型可能会随意随机调用,影响业务效率并产生潜在风险。DiaFORGE框架的提出正是为了应对这一现实挑战,它通过三个核心阶段引导模型学会主动识别并解决模棱两可的工具调用场景。首先,通过合成带有人物角色设定的多轮对话数据,让模型置身于需要反复确认、区分极其相似工具的真实对话环境中。这种仿真训练场景强化了模型推理和消歧义的能力,使其能够在实际应用时自动提出关键澄清问题,准确定位用户真正需求。其次,DiaFORGE对多种规模的开源大语言模型进行了监督性微调,涵盖3亿至700亿参数区间,在训练过程中整合了详细的推理轨迹。
这不仅促进模型理解多步骤推理过程,还提升了模型针对复杂参数缺失情况的补全能力。相比未经过该流程的模型,经过DiaFORGE微调的模型表现出更高的工具调用成功率和更强的容错能力。第三阶段,研究团队设计了动态评估工具DiaBENCH,让训练好的模型在真实的代理环境中反复执行任务,由此获得端到端的成功率和完成质量指标。这种在线式评测突破了传统静态评测的限制,更贴合实际业务场景,确保模型不仅关注回答的字面准确,更强调任务实际完成度。基于DiaFORGE微调训练的模型在DiaBENCH测试中成功率相较于现有主流强基线模型提升明显。其中,相比优化提示版本的GPT-4o成功率增加了27个百分点,较Claude-3.5-Sonnet提升近50个百分点,展现出极佳的性能提升潜力。
此外,研究还公开发布了一个包含5000份高质量企业API规范及其对应消歧义对话的开源数据集,这为后续研究与工业级应用提供了宝贵的资源和基线。该数据集覆盖了丰富的真实业务场景,能够帮助开发者和研究者快速构建更加健壮、灵活的工具调用大语言模型。消歧义核心的微调策略对建设安全可靠的企业智能助手具有深远影响。诸如数据隐私保护、错误调用带来的经济损失及客户体验下降等企业在智能自动化推广过程中极为敏感的问题,都可以通过该技术得到有效缓解。模型主动探寻用户意图,避免盲目调用,显著降低了潜在风险,使大语言模型能够以更成熟、更可控的形态投入实际生产环境。未来,随着企业数字生态的不断丰富,API种类和功能将持续增加,工具调用复杂度也将相应提高。
依赖单一模型推断将难以适应日益多样化的需求,消歧义驱动的训练和评估方法将成为主流方向。此外,结合多模态信号、多轮交互反馈、以及强化学习等技术,有望进一步完善大语言模型的工具调用准确性和用户体验。总而言之,基于消歧义的微调框架通过模拟真实交互环境、强化多步骤推理训练和动态评估,成功解决了大语言模型工具调用过程中的关键难点。这不仅推动了学术界对企业级智能助手研发的前沿探索,更为实际应用中构建更加智能、可靠的自动化工具调用代理提供了坚实基础。随着相关数据和开源工具的持续丰富,相信该领域未来将涌现更多突破,助力企业实现智慧升级,迈向更高效、更安全的数字化转型之路。