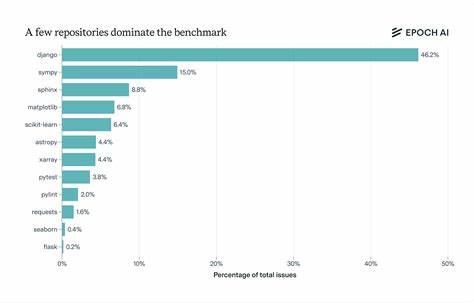
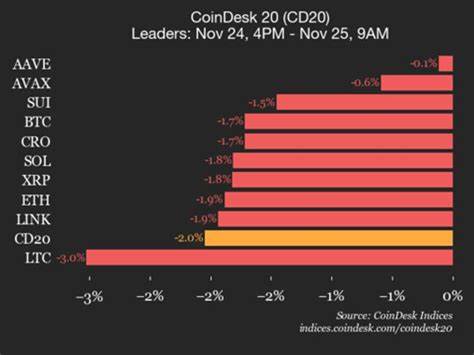
随着人工智能技术的迅猛发展,大型语言模型(LLM,Large Language Models)逐渐成为推动自然语言处理领域进步的重要力量。它们具备强大的语言理解和生成能力,广泛应用于自动写作、智能客服、内容创作等领域。然而,在这背后却存在一个关键且不可忽视的问题 - - 非确定性。非确定性现象不仅影响了模型的稳定性和输出的可信度,也带来了安全隐患和实际应用中的难点。深入探讨大型语言模型中的非确定性,对于推动人工智能技术的健康发展和应用创新具有重要意义。 初步理解非确定性需要明白大型语言模型的工作机理。
LLM是基于海量数据通过复杂神经网络训练得来的语言理解工具,其输出结果往往不是唯一且确定的,而是充满多样性和不确定性。这种不确定性一方面源于模型本身的架构设计和参数初始化,另一方面则与生成时所采用的采样方法密切相关。具体而言,当输入相同的文本提示时,模型可能产生不同的回答,这种现象在实际应用中尤为显著,这使得用户体验存在一定的波动性和随机性。 非确定性的存在在一定程度上带来了语言模型生成内容的多样性和创造性,丰富了输出结果,促进了创新应用的出现。然而,它也极大地增加了对输出结果进行有效控制的难度。在安全性方面,非确定性导致模型可能输出不准确、甚至有风险的内容,如误导性信息、偏见言论或敏感内容,给使用者和社会带来潜在危害。
此外,非确定性也对模型的可解释性和可验证性构成挑战,限制了其在某些高风险、高要求场景中的应用。 面对非确定性带来的挑战,研究人员和开发者正积极探索多种策略以降低其负面影响。其中,优化采样策略成为关键方向之一。通过引入温度调节、束搜索、top-k采样等方法,可以在一定程度上平衡生成内容的多样性和一致性。同时,加强训练数据的质量与多样性,设计更合理的模型架构,也有助于提升模型的稳定性和可控性。此外,结合人工审核和后期过滤机制,是确保大型语言模型输出安全性和准确性的实用方案。
另一方面,非确定性还催生了新的应用理念和技术创新。其所体现的"随机性"模式为创意写作、文案生成、智能对话系统赋予了更多灵活性,使得模型可以根据不同场景和用户需求,生成更丰富且富有个性化的内容。在教育、娱乐、辅助决策等领域,这种特性正发挥出独特价值。非确定性的合理利用,有望促使人工智能更好地与人类合作,共同创造更多可能。 此外,非确定性引发的伦理与安全问题也日益受到关注。如何防止模型产生有害内容,如何避免算法偏见的加剧,成为业界和学界共同面临的重大课题。
透明化模型训练过程、设立严格的监管标准、加强对用户隐私的保护,都是构筑安全可持续生态的重要环节。面向未来,只有在坚持技术创新的同时,注重规范和责任,才能推动大型语言模型技术健康发展,惠及更广泛的社会公众。 综上所述,非确定性是大型语言模型发展过程中不可避免且具有双重性的特点。它既带来丰富的创造力和灵活应用空间,又带来安全风险和控制难题。深入理解非确定性的本质,开发有效的缓解和利用策略,是当前乃至未来人工智能研究的核心方向。随着技术不断进步,我们有理由相信,未来的语言模型将在非确定性的基础上,实现更为精准、可靠且人性化的智能交互,推动人类社会迈向更加智能和美好的时代。
。