在当今数字化时代,网络爬虫(Scraping the Web)已成为一种不可或缺的技术。它不仅能够帮助企业分析市场趋势、监测竞争对手,还能为科研人员提供宝贵的数据支持。然而,随着技术的进步,网络爬虫的使用引发了不少关于数据隐私与伦理的讨论。本文将深入探讨网络爬虫的定义、工作原理、应用场景以及相关的法律与伦理问题。 网络爬虫,简单来说,就是一种自动访问网页并提取信息的程序或工具。通过编写代码,爬虫能够模拟用户在网页上的操作,收集如文本、图片、链接等多种形式的数据。
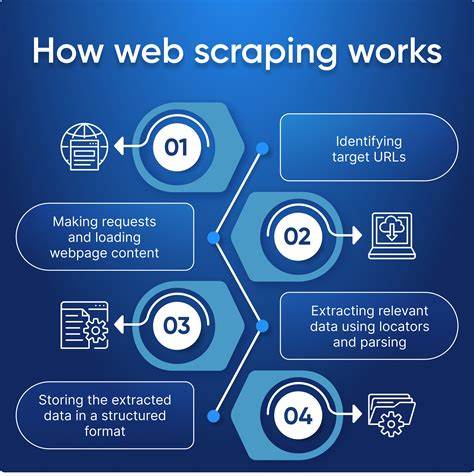
这项技术广泛应用于数据分析、市场研究、学术研究等领域。例如,电商平台可以通过爬虫获取竞争对手的价格信息与产品评价,从而制定更具竞争力的营销策略。科研人员也可以利用爬虫收集大量的文献和数据,进行深入的分析和研究。 网络爬虫的工作原理主要分为三个步骤:请求发送、数据抓取和数据存储。首先,爬虫根据设定的目标网址发送请求,访问网页。当网页返回响应后,爬虫解析网页内容,提取所需的信息。
最后,提取的数据会被存储到数据库或者电子表格中,供后续分析使用。在这个过程中,爬虫可以利用各种技术,如XPath和正则表达式,来定位和提取信息。 尽管网络爬虫具有众多优势,但在实际应用中也面临许多挑战和争议。首先,许多网站对爬虫行为存在限制,一些网站在其服务条款中明确禁止使用爬虫抓取数据。此外,频繁的访问请求可能会对网站造成负担,甚至影响其正常运营。因此,爬虫开发者需要遵循“礼貌爬虫”的原则,合理控制请求频率,避免对目标网站造成影响。
在法律层面上,网络爬虫的合法性问题也越来越受到关注。许多国家对此已有相关法律法规。例如,美国的《计算机欺诈和滥用法》(CFAA)就规定了未经授权获取计算机数据的行为可能构成犯罪。在中国,随着网络安全法和数据安全法的实施,网络爬虫的合规性问题愈加突出。企业和个人在使用爬虫时,必须充分了解相关法律法规,以避免可能的法律风险。 进一步说,网络爬虫在数据隐私方面也引发了广泛的讨论。
随着大数据时代的到来,个人信息的收集和使用成为热点话题。一方面,爬虫技术能够为商业机构提供精准的用户画像,帮助其进行精准营销;另一方面,用户的信息安全问题也日益突出。如何在利用爬虫技术获取数据与保护用户隐私之间找到平衡,成为亟需解决的问题。 在技术发展方面,网络爬虫工具也在不断创新和进化。近年来,随着人工智能和机器学习的崛起,越来越多的网络爬虫工具开始集成智能化功能。一些工具不仅可以抓取网页数据,还能对数据进行自动分析和处理,极大提高了工作效率。
例如,利用自然语言处理技术,爬虫可以自动识别网页中的关键信息,为用户提供有价值的见解。 总结而言,网络爬虫是一种强大而实用的工具,可以为多个领域提供丰富的数据支持。然而,随着其应用场景的不断扩大,相关的法律及伦理问题也愈加复杂。在使用爬虫技术时,开发者和用户需认真考量数据使用的合法性和合规性,以确保在获得利益的同时,尊重他人的数字权利。在这个信息爆炸的时代,能够合理地利用网络爬虫,将为个人和组织带来巨大的机遇与挑战。 未来,随着技术的不断革新和法律的逐步完善,网络爬虫有望在更广泛的领域得到应用。
无论是在科技、金融还是医疗行业,如何有效地利用爬虫技术获取和分析数据,将成为行业发展的关键因素。同时,我们也期待在数据隐私和伦理方面取得更多的进展,实现技术与道德的双重平衡。通过加强教育和宣传,提高公众的网络安全意识,或许能够为网络爬虫的健康发展创造更有利的环境。