在当今信息爆炸的时代,如何有效地处理和分析海量数据成为了一个亟待解决的问题。主题建模(Topic Modeling)作为一种强大的文本分析技术,逐渐走入大众视野。它能够帮助研究人员、数据科学家及企业分析师在众多文档中识别出潜在主题,从而提取有价值的信息。然而,如何自动确定主题的数量却一直是一个具有挑战性的任务。近期,一种基于潜在狄利克雷分配(Latent Dirichlet Allocation, LDA)的自动主题数量确定方法引起了广泛关注。 主题建模的核心是通过对文档进行分析,找出其中的主题。
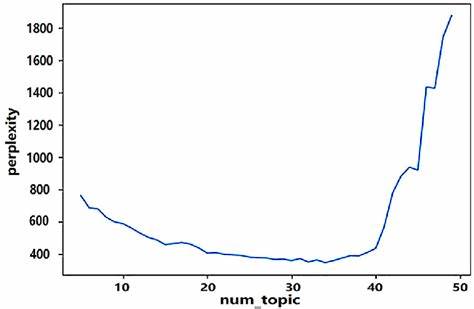
这些主题不仅能够揭示文档的内容结构,还能够通过聚类相似文档来帮助用户理解信息。在以往的研究中,研究人员往往需要依赖经验或试错法来选择合适的主题数量,这个过程既耗时又费力。最新的研究表明,利用一些先进的指标和算法可以自动识别最佳主题数量,从而简化整体流程。 为了实现这一目标,研究者们引入了多种评价指标,比如“Griffiths2004”、“CaoJuan2009”和“Arun2010”。这些指标通过评估模型的拟合度来帮助确定最佳主题数量。以“CaoJuan2009”为例,它通过计算每个主题的生成概率来评估模型的质量,寻找最佳的主题数量以提高主题的分离度。
而“Arun2010”则通过评估文档的主题共享情况,提出了一种全新的模型评估策略。通过集成这些指标,研究人员能够更精确地定位到最佳主题数量。 在具体实现过程中,使用R语言的“ldatuning”包,研究人员能够有效地处理文本数据。首先,需要对数据进行预处理,包括去除停用词、清洗文本和构建文档-词项矩阵(Document-Term Matrix)。清洗数据是至关重要的一步,因为杂乱的数据会对模型的建模效果产生负面影响。在处理后,研究者们可以使用LDA模型来进行主题建模,并通过并行计算加速模型的训练过程。
为了可视化主题模型的结果,LDA模型提供了直观的输出,研究人员能够通过图表和图形清晰地看到各个主题之间的关系。这不仅提高了结果的可理解性,还为进一步分析提供了便利。使用LDA可视化工具,用户能够展开对主题的深入探索,识别出每个主题的核心关键词以及对应的文档分布。 除了技术创新,自动主题数量确定的研究还引发了关于信息处理与数据价值的问题讨论。随着各行各业对大数据的依赖日益增强,如何运用有效的数据分析工具提升决策效率,成为许多企业关注的焦点。这种自动化的主题建模技术不仅可以显著减少人力成本,还能提高分析的准确性,为商业决策提供强有力的支持。
在学术界,主题建模的兴起为自然语言处理(NLP)领域注入了新的活力。研究者们通过深入的理论分析和应用探索,使这种技术不断成熟,并拓展了其应用场景。从社会科学到市场营销,从舆情分析到学术研究,主题建模都展现了其巨大的潜力。未来,随着算法的不断进步和计算能力的提升,自动化主题建模将能处理更加复杂和海量的文本数据,深化我们对数据的理解。 然而,尽管自动化主题数量确定的技术进步显著,但在实践中依然面临一些挑战。首先,不同的数据集具有不同的特性,统一的模型可能无法适应所有情况。
因此,在使用这些技术时,研究者需要根据具体数据的性质,灵活调整模型参数。其次,虽然我们拥有众多自动化工具,但人工审阅和判断依然是不可或缺的一部分。人类的直觉和经验往往能够提供更深刻的见解,这对模型的结果进行合理解释和应用至关重要。 随着技术的不断发展,主题建模的未来将更加广阔。我们可以预见,在未来的几年中,自动化主题建模将更加普及,成为数据分析的标准工具之一。这不仅能够帮助企业和研究机构从大量的数据中提取有用的信息,还能提升整个社会对信息分析和决策的能力。
最终,随着科技的进步和社会对数据价值认识的加深,主题建模将为构建更加智能化的社会提供坚实的基础。 总的来说,主题建模与自动化主题数量的确定是数据分析领域的重要发展之一。无论是在学术研究、商业分析,还是在社会发展中,这项技术都展现出不可忽视的潜力。通过不断的探索与实践,我们有理由相信,未来主题建模 será 继续发展,并为我们揭示更加深刻的数据真相。