随着人工智能技术的快速发展,AI模型在代码自动生成、错误修复和功能实现等软件工程领域的应用日益广泛。传统的软件工程AI评测基准面临着诸多限制,例如数据污染、任务单一、问题过于简单以及测试的不稳定性等,难以全面反映AI在真实开发环境中的实力。为应对这些挑战,SWE-Bench Pro公开数据集应运而生,成为衡量AI智能代理解决复杂软件工程问题能力的全新标杆。SWE-Bench Pro带来的不仅是更严苛的评测标准,也代表着AI软件工程领域迈向更真实、更多样化、更具挑战的测试阶段。Sve-Bench Pro由多个高质量开源与私有代码库构成,涵盖消费者应用、企业级服务和开发者工具等多种软件类型。这种多样性使得任务不仅仅局限于常见的简单库函数,而是真实反映了现代软件开发中遇到的复杂代码结构和多样业务需求。
公开数据集中精选了采用强制开源许可证(例如GPL)的仓库,这种策略从法律和数据管理角度有效降低了培训数据与测试集之间的重叠风险,确保了模型测试结果的真实性与泛化能力。数据集包含超过七百个任务,平均每个任务需要对四个文件进行编辑,改动代码行数达到一百多行,表明任务难度远超市面上许多其他软件工程基准。这不仅考验模型的代码理解和生成能力,还让AI必须具备跨文件、多模块综合解决问题的能力。每个任务的设计都经过严格的四阶段流程。首先从精选的公共和私有仓库中挑选代码,接着由专业工程师构建Docker环境确保代码及测试用例能无误执行,然后通过自动检测的版本提交历史,筛选出真正修复bug或新增功能的代码块,最后由人工专家补充详细的问题描述和需求说明,使得AI评测不仅关注语法正确,更关注语义层面的代码输出和功能实现。测试系统中的核心评价指标为"解决率",此指标仅在代码补丁能够使之前失败的测试通过且所有之前成功的测试依旧维持通过状态时才被视为通过。
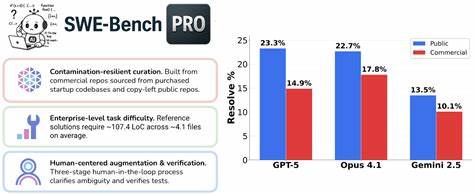
这样的严格标准保证了AI模型的改动既解决核心问题又不会引入新的错误,彻底检验模型在真实软件维护和开发中的实用性。在与前身SWE-Bench Verified的对比中,SWE-Bench Pro的难度提升显著,顶级模型在旧版中能取得70%以上的解决率,而在SWE-Bench Pro公开数据集中,最高分仅在23%左右徘徊。更进一步,私有代码集中的测试结果显示模型的泛化能力依然有限,解决率降低至17%左右,凸显真实工业环境中AI应用仍存挑战。从具体表现看,不同编程语言对AI模型的难度呈现出明显差异。Go语言和Python的任务整体解决率较高,多数顶尖模型突破了30%,而JavaScript和TypeScript的任务表现波动较大,部分模型在这两种语言环境下效果甚微。此外,任务所属代码库的复杂程度亦对结果产生深远影响。
某些仓库的任务解决率普遍偏低,反映其代码架构复杂或文档资料有限,而其他仓库中则出现模型解决率超过半数的情况,显示模型在部分领域具备较强适应能力。从模型版本角度观察,最新一代AI模型如Claude Opus 4.1和OpenAI GPT-5不仅在整体得分上领先,还展现出更均衡稳定的性能表现。它们在多语言、多仓库的任务中持续表现出色,远超部分表现波动较大的中小型模型。这说明规模和训练策略的进步使得AI代理更加强大,在应对跨领域和多任务场景时具备更好的泛化和鲁棒性。任务复杂度与模型性能呈负相关,随着要求修改的代码行数增加和涉及文件数量增多,模型的解决率明显下降。这与现实软件开发中大型变更比微小调整更具挑战性一脉相承,也提示未来的AI模型需要更深入的代码理解和长期依赖处理能力。
SWE-Bench Pro不仅提供了详实的数据和严格标准,还注重生态合作与技术积累。开发团队感谢了工程师、注释员及早期合作的创业公司,为构建质量环境、验证测试及丰富任务描述付出了巨大努力。同时,开源社区的贡献也为数据集基础库提供了有力支持。整体来看,SWE-Bench Pro公开数据集无疑是AI软件工程领域的里程碑。它打破过去评测的局限,用更贴近真实开发环境的任务和更严苛的质量控制,推动了AI智能代理解决软件工程挑战的边界。未来,随着模型技术的持续进步和数据集覆盖面的扩大,期待AI能在软件开发中发挥更大作用,助力开发者提升效率,提升代码质量和项目交付速度。
对于研究人员和开发者而言,深入理解并参与SWE-Bench Pro的测评,将有助于优化模型设计和应用策略,强化AI在软件开发生命周期中的实用性与安全性。通过这一前沿数据集,我们看到了AI助力软件工程的巨大潜力,也明确了通往真正智能开发的道路依然漫长且充满挑战。 。