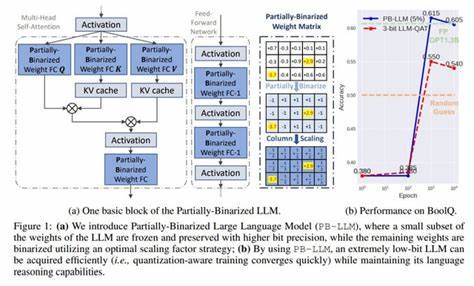
在现代计算机系统中,操作系统内核是保障一切运行的基石,而内核开发一直以来被视为高级编程和系统架构设计的复杂领域。随着人工智能的兴起,尤其是大型语言模型(Large Language Models, 简称LLMs)的蓬勃发展,内核开发迎来了新的机遇。大型语言模型以其强大的自然语言处理和代码生成能力,正在逐步改变内核开发的工具链和工作流程,为开发者提供前所未有的辅助支持。 大型语言模型本质上是一种巨大的概率状态机,通过分析和匹配大量的语言模式,能够生成符合上下文的文本或代码。不同于内核中常见的确定性状态机,LLMs的状态转移具备高度的概率特性,使其能够在复杂且多变的环境中给出合理预测。例如,当输入“Linux内核是用……编写的”时,模型通常会回答“C语言”,但也有概率给出“Rust”或“Python”等答案,显示了灵活的语言理解能力。
这类模型在内核开发中的应用最明显的一个方面就是代码辅助。开发者可以利用LLMs来生成小规模、明确任务的代码补丁,提高代码编写效率。开源内核社区已有案例表明,LLM生成的代码补丁不仅能正常运行,还包含详尽的变更日志和自测内容,显著提升补丁的可维护性和质量。此外,针对那些非英语为母语的开发者,LLMs在撰写高质量提交说明和文档方面同样发挥重要作用,减少语言障碍带来的困扰。 内核开发中的一个典型挑战是稳定版本的维护和安全漏洞修复。过去,维护者每天需要审查成百上千的补丁以判断其重要性并决定是否回溯合并。
面对如此庞大的代码变更量,人工审核既耗时又难以实现高效。这里,基于LLM技术的自动选择工具——如AUTOSEL便成为重要助手。该工具通过构建补丁的“嵌入”(一种将文本转化为数学向量的技术,保留语义信息),快速匹配相似的历史补丁,从而筛选出可能需要回溯的安全修复或功能改进。AUTOSEL集成多种模型投票决策,保证筛选结果的可靠性,并为人工审核节省宝贵时间。 此外,检索增强生成技术(Retrieval Augmented Generation, RAG)为LLMs带来了更为精准的知识定位能力。RAG结合了信息检索和语言模型生成的双重优势,允许模型在面对未知问题时主动查询内核代码库或文档,避免纯粹依赖训练数据时的“虚构”行为。
应用RAG技术,不仅提升了生成代码的准确性,也为内核开发者提供了透明易懂的代码生成理由,增强了整个工作的可解释性。 除了代码层面的辅助,LLMs还促进了内核安全漏洞的管理。随着内核项目开始自行分配CVE编号,相关的脚本和工具逐渐被重新设计和实现,部分采用了Rust语言。虽然Rust对内核开发者来说是一种相对陌生的语言,但LLMs能够快速帮助团队实现高质量的重写版本,包括测试和文档,为提升工具可维护性和安全保障打下坚实基础。同样,LLM辅助的漏洞筛查流程也在逐渐成熟,用于自动识别可能关联的安全修复,提高漏洞处理的时效和准确度。 然而,LLMs的介入也带来了新的争论与思考。
法律层面上,LLM生成的代码版权归属尚无明确定论,特别是在开源协议和贡献者签署的代码提交协议(DCO)背景下,存在潜在的合规风险。社区内讨论是否应当对使用LLM生成的代码做出特别声明,以及如何保护项目和开发者权益成为热点话题。技术层面则不乏对LLMs“幻觉”现象的担忧,即模型在没有确切依据时生成虚假代码或错误逻辑,可能引发安全和稳定性问题。此外,过多依赖LLMs可能影响开发者的深入理解和技能传承,构成未来人才培养的隐忧。 尽管如此,社区普遍认可LLMs作为辅助工具的巨大价值,强调其不能替代人类专家的决策和审核职责。有效的人机协同机制是发挥LLMs优势的关键。
通过让模型承担重复性、机械性的任务,释放开发者的创造力和判断力,能够在提升效率的同时保证代码质量和安全性。未来,随着LLM技术的成本下降和模型能力的提升,预计更多的自动化代码审查和漏洞发现功能将实现,使内核开发更加智能化和敏捷。 总的来看,大型语言模型正在成为内核开发领域内不可忽视的新力量。从自动代码生成到补丁筛选,从安全漏洞管理到文档撰写,LLMs正一步步融入内核开发生命周期,助力社区缓解人力不足和任务繁重的压力。面对挑战,社区通过规范化流程和技术创新,积极推动技术民主化与透明化,确保内核项目的开放性和可持续发展。未来,结合更多上下文感知和知识更新机制的高级语言模型,将有可能彻底改变内核开发范式,推动开源操作系统迈入崭新的智能时代。
。