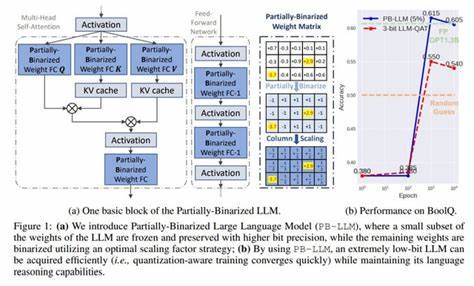
随着人工智能技术的不断进步,大型语言模型(Large Language Models,简称LLMs)在自然语言处理领域展现出前所未有的潜力。它们不仅在文本生成、机器翻译、问答系统等任务中表现出极高的准确率和灵活性,也推动了产业界和学术界对深度学习模型应用的极大关注。然而,这些大型模型通常伴随着庞大的参数量和巨大的计算开销,使得其在资源受限的环境中部署面临重大挑战。传统的模型压缩技术,如权重量化、剪枝、知识蒸馏等,虽有所帮助,却难以满足对极端低比特量化的需求,尤其是在保障模型性能和推理速度之间找到理想平衡更是难上加难。近日,LCD(Low-bit Clustering Distillation)作为一种创新性的解决方案应运而生。LCD方法融合了低比特聚类量化与知识蒸馏技术,通过精心设计的优化策略,既实现了对模型参数的极端压缩,又有效保护了模型的推理能力和准确率。
相比于传统量化方法,LCD能够在2至3比特的超低位宽下维持较高的语言理解和生成质量,为大型语言模型的实际应用提供了现实可行的变革路径。LCD的核心优势之一在于其聚类基础的量化机制。通过将模型权重划分为若干簇,系统只需存储簇中心值而非每个独立权重,有效减少存储需求和内存访问压力。得益于这一机制,模型参数的表达更加紧凑,一方面降低了硬件资源消耗,另一方面为后续的推理加速奠定了基础。与此同时,知识蒸馏被巧妙地嵌入到训练流程中。通过从预训练的高精度教师模型中提取知识,用低比特聚类模型作为学生模型进行学习,确保了低精度模型能够最大程度地模仿教师模型的表达和决策逻辑。
知识蒸馏不仅弥补了低位宽量化带来的信息损失,还进一步提升了模型的泛化能力,使得低精度模型在保持轻量化优势的同时展现出优异的综合表现。为了进一步提升推理效率,LCD还引入了激活压缩技术和基于查找表(LUT)的设计。激活压缩通过对模型内部激活值进行平滑处理减少了计算复杂度,降低内存带宽占用;而查找表设计则通过预先计算部分操作结果,实现了运算过程的快速替换,从硬件层面加速推理过程。这些技术协同作用,为用户带来了高达6.2倍的速度提升,显著缩短了模型响应时间,满足了实时性强的应用需求。LCD技术以其实验表现令人印象深刻。对多个标准大规模语言模型和数据集进行测试,LCD在保持模型准确率的同时实现了极致的压缩率,优于目前主流的量化和蒸馏方法。
其成本效益优势明显,既降低了存储和计算资源的使用,也极大提升了部署的灵活性和用户体验。展望未来,极端低比特聚类结合知识蒸馏的技术路径有望成为大型语言模型压缩领域的重要方向。随着边缘计算、移动设备和物联网等场景对高性能AI的需求不断增长,具备更低资源占用和更快推理速度的模型显得尤其关键。此外,进一步优化聚类算法、蒸馏策略和硬件适配技术,将推动这一方法在更多复杂任务上的应用与突破。总之,LCD代表了当前降低大型语言模型部署门槛的前沿技术之一,为AI普及和智能化进程注入了强大动力。通过将模型量化与知识提炼深度整合,LCD不仅解决了大模型大小和速度的瓶颈,也为未来智能技术的广泛落地创造了无限可能。
随着研究的不断深入和产业界的积极采纳,极端低比特聚类及其扩展应用无疑将在人工智能领域引发新的变革浪潮。





![本文深入探讨了如何利用经济实惠的方法结合视觉模型与期望概率(E[P])进行用户研究,揭示了在有限资源条件下实现高效用户行为预测与分析的创新路径。](/images/929F34A8-1612-41DC-8D55-16C1A46ED1A9)