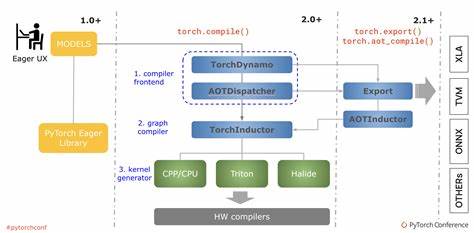
随着深度学习的发展,PyTorch逐渐成为研究者和工程师的首选框架。为提升训练和推理速度,PyTorch引入了torch.compile功能,它通过静态编译加速模型执行。在torch.compile的背后,有一套复杂但关键的机制——Guards。本文将详细剖析Guards的工作原理,分析其带来的性能成本,并分享实用的优化策略,帮助用户更好地利用torch.compile进行模型编译与加速。 torch.compile是PyTorch的一个重要创新,它通过将PyTorch的动态图转换为静态图来实现加速。这一转换依赖于捕获并跟踪模型的执行路径,以确保优化后的代码在运行时的行为与原模型一致。
Guards机制即在此过程中发挥重要作用。Guards是一种动态检查机制,它在编译生成的代码中插入条件判断,用以验证运行时输入和环境是否满足编译时假设。若Guard条件失败,就会触发回退机制,返回动态图执行路径,从而保证计算的正确性。 Guards的核心作用是维护编译代码的正确性与稳定性。在实际应用中,深度学习模型通常拥有复杂的控制流和多样的输入形态,静态编译时难以预见所有运行时情况。通过插入Guards,可以在执行前动态验证关键条件是否符合预期。
此举有效避免了因输入变化引起的错误计算,但同时也带来一定的性能开销。理解决定Guards性能成本的因素,对优化编译模型非常关键。 Guards带来的成本主要体现在运行时的额外条件判断和回退处理。每当执行到涉及Guard的代码时,系统需评估这些条件,确保当前运行状态与编译假设一致。虽然单个判断的成本较低,但大量Guards叠加可能导致显著的延迟。此外,Guard失败时触发的回退路径,可能涉及重新解释执行或重新编译,进一步增加执行时间。
此外,频繁的Guard失败会使编译优势大打折扣,使得模型执行效率无法得到充分提升。 为了最大化torch.compile的性能优势,合理设计和优化Guards尤为重要。首先,减少Guards的数量是关键,可通过静态分析和模型简化来降低需要动态验证的条件。减少输入动态变化,例如限定输入形状和类型的稳定性,也有助于减少Guard触发频率。其次,针对常见且代价高昂的Guard条件,可以采用缓存机制,如利用内存中的状态缓存验证结果,避免重复计算。再次,合理使用批处理和数据预处理策略,提升整体计算的稳定性,从而降低Guard的误触发率。
最后,积极关注PyTorch社区对torch.compile及Guards的最新优化方案,及时升级框架版本,利用官方提供的新特性和性能改进。 在具体实践中,用户应结合模型特点和任务需求,动态调整和测试Guard策略。例如,对于形状变化频繁的模型,采用输入归一化手段确保形状一致,可以显著减少Guard开销。对于包含复杂控制流的模型,合理拆分子模块并分别编译,有助于局部优化并控制Guard数量。借助性能分析工具,实时监控Guard的执行时间和失败频率,帮助精准定位性能瓶颈。此外,文档和社区案例中积累的优化经验,也为Guard调优提供了宝贵参考。
未来,随着PyTorch对torch.compile的持续演进,Guards的设计和实现将不断完善。通过更智能的静态推断技术和动态检查算法,预计Guards的性能负担会进一步降低,同时增强其适应性和鲁棒性。此外,结合硬件加速器和分布式计算的需求,Guard机制也将不断适配多样化执行环境。开发者应保持对官方更新的关注,积极尝试并反馈使用体验,推动生态系统共同进步。 综上所述,torch.compile中的Guards机制是确保编译代码安全可靠运行的关键所在。虽然Guards带来了不可忽视的性能开销,但通过合理设计和细致优化,可以最大限度地发挥torch.compile的加速潜力。
掌握Guards的工作原理和优化方法,将使深度学习开发者在模型编译过程中更加游刃有余,实现高效且稳定的加速效果。未来随着技术创新,我们有望看到更智能、更轻量级的Guards机制,为PyTorch用户带来更出色的使用体验和性能提升。