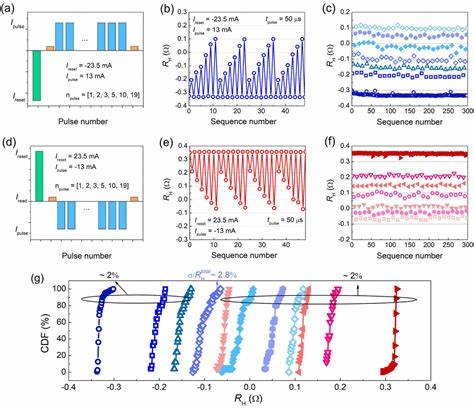
目标检测作为计算机视觉中的核心任务,广泛应用于自动驾驶、智能安防、医疗影像分析等诸多领域。高质量的训练数据尤其关键,而传统的目标检测标签生成过程通常耗时长、成本高,制约了大规模数据集的构建和模型的普适推广。在此背景下,自动标注数据技术迅速兴起,成为驱动目标检测领域发展的重要力量。该技术旨在通过利用已有预训练模型的知识,实现无需人工干预的自动标签生成,为轻量级检测模型的训练提供精准且高效的基础。自动标注数据技术的出现,突破了以往依赖人工标注的桎梏,为目标检测的开发与商业应用开辟了全新的可能。研究人员将多种视觉语言基础模型配置为自动生成伪“真实”标签,这些标签可直接嵌入现有目标检测训练框架,有效支持各种轻量级检测算法的训练。
此举不仅节省了传统标注所需的资源成本,也维持了模型性能的竞争力,实现了性能和效率的最佳平衡。当前,视觉语言模型结合图像理解与自然语言处理的能力,能够精准识别场景中的对象类别、位置乃至属性,提供强大的信息推理支持。通过对这类模型的巧妙配置,自动标注方法不仅能够适应不同的应用场景,还能灵活应对复杂多变的视觉内容。多项实验验证了这一方法的实用性与泛化能力,涵盖了多种数据集和检测模型,全面展示了其在不同条件下的性能表现和适应度优势。实验结果显示,与传统人工标注数据相比,自动标注生成的伪标签能够在一定程度上保持甚至提升检测准确率,尤其在数据规模和标注效率方面优势显著,极大缩短了模型训练准备时间。此外,自动标注技术在结合轻量级检测模型时表现尤为突出。
相比于依赖大型复杂模型的无监督或弱监督目标检测方法,此技术兼顾了计算资源的节约和实际应用的实时需求,适合嵌入式设备及移动端应用场景。凭借其无须人工参与以及高效标签生成的特性,自动标注为数据高质量与模型训练之间搭起了桥梁。它不仅降低了机器学习应用入门门槛,也助于中小企业和研究机构在资源有限的情况下实现智能目标检测研发。随着自动标注技术的成熟,其标准化的流程和可复用的标签生成策略逐渐形成,形成了一套科学合理的自动标注基准,为后续相关研究的开展提供了重要参考。自动标注数据方法的进步还推动了目标检测模型的持续优化,使得更多新颖的检测算法能够在更大规模、更多样化的数据上进行验证与训练,促进了领域整体技术水平的跃升。展望未来,结合更先进的视觉语言模型及多模态融合技术,自动标注有望实现更加精准、智能化的标签生成,进一步提升无监督目标检测的性能瓶颈。
此外,自动标注技术与半监督、迁移学习等策略的结合,也将加速目标检测领域对复杂现实环境的适应能力,推动智能视觉系统向更广泛的应用场景延展。自动标注数据技术不仅革新了数据准备流程,同时激发了机器视觉模型构建的新思路。从理论研究到实际应用,自动标注正成为连接数据、模型与智能分析的关键纽带。其背后的理念强调 leveraging 现有强大模型的知识来服务下游任务,为数据匮乏问题提供创新解决方案。总体来说,自动标注数据在目标检测中的应用标志着视觉智能领域正在进入一个更加高效、智能和普及的新阶段。通过大规模、低成本数据生成和高效模型训练,该技术有望加速人工智能走向普惠普及,带来更广泛社会价值和商业潜力。
未来随着硬件算力提升和算法革新,自动标注将实现更强的自适应能力及跨领域泛化,进一步巩固其在目标检测及整个计算机视觉领域的中流砥柱地位。