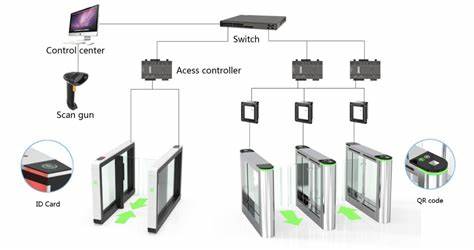
稳定标签定位算法作为图像处理和计算机视觉领域中的关键技术之一,因其在区域内寻找最佳标签位置的独特优势,受到了广泛关注。它通过分析像素周围的连通区域,精准定位区域内最稳定的点,从而避免标签落于边缘或不合适的位置。这种方法不仅适用于地图标注、图像分割结果的标记,也在数字艺术与图像着色等创意应用中展现出了其重要价值。尽管算法设计优雅且直观,实现上却面临着性能瓶颈,尤其是在大规模像素数据处理时,算法的计算量呈现出指数级增长,导致传统的CPU串行计算无法满足实际需求。针对这一挑战,实现算法的并行化和硬件加速变得尤为关键,GPU因其天生的并行计算特性,成为理想选择。传统的稳定标签定位算法核心是对每个区域内的像素点,分别计算其在四个主方向上连续相同值像素的数量,乘积越大代表中心越稳定。
最初的实现方式通过遍历每个像素点及执行方向计数函数完成,其缺陷显著体现在执行效率和计算负载上。随着区域数量和图像分辨率的提升,这种方法所需的计算时间急剧增加,严重制约了算法的应用范围和实时性。为解决性能瓶颈,研究者开始探索基于NumPy的向量化实现。利用NumPy强大的数组运算能力,可以减少Python层级的循环,借助底层C语言的高效实现显著提升性能。同时将算法结构重构为矩阵操作,如扫描行或列,进行连续像素计数,从而实现批量计算,这也是算法现代化的第一步。更进一步,为了充分利用现代硬件,研究者引入了CuPy库,它是兼容NumPy接口的GPU加速数组库。
将算法切换为基于CuPy实现后,在支持CUDA的NVIDIA显卡上,能够并行处理数百万像素数据,大幅提升计算速度。然而实践中发现,单纯的CuPy重写并没有带来预期的性能飞跃,甚至在某些硬件配置下,GPU版本的表现反而逊色于CPU版本。这一现象引发了对GPU计算特性的深入分析。关键瓶颈在于算法内部存在的遍历循环,其本质是依赖前一像素结果的序列性操作,无法很好地被GPU的并行架构利用。此外,在循环中频繁调用GPU操作导致大量计算核启动开销,成为性能制约的主要因素。GPU最擅长处理大规模、无依赖的并行任务,而序列依赖型的操作会成为其软肋。
为此,解决之道是减少Python层面的逐步循环,让GPU一次性完成更多任务,减少核启动次数。这里,Numba技术的引入提供了有效途径。Numba是一个针对Python的即时编译器,支持将特定函数编译为高效机器码,同时具备对CUDA的支持,使得开发者能以Python+Cuda内核的形式编写GPU内核,实现真正意义上的设备端并行执行。通过用Numba重写扫描函数,将行扫描操作映射为每个GPU线程处理整行数据,从根本上消除了Python循环中频繁调用GPU核的瓶颈。此改进不仅充分发挥了GPU的并行能力,也将数据访问优化为更符合GPU内存访问模式的形式,减少了数据传输和延迟。经过该优化后,整体程序在GPU上的运行效率提升达到十五倍以上,显著优于此前的纯CuPy实现,同时也超过了多核CPU环境下的纯NumPy版本。
这一优化的成功,为稳定标签定位算法的实时应用提供了坚实的技术保障。借助现代GPU和编译技术,复杂的图像处理任务将能够以更低的资源消耗完成更高的计算量,满足智能图像分析及交互式应用的需求。值得注意的是,为了兼顾不同硬件环境的适配性,算法实现中采用了灵活的运行时环境检测机制。当检测到有支持CUDA的GPU及CuPy环境时,程序切换至GPU加速路径,反之则退回至CPU的NumPy实现。通过将不同平台的数组与运算接口统一至同一个别名(如xp),代码保持简洁且具备高度移植性,降低了维护成本。综上所述,稳定标签定位算法的并行化不仅是单纯的性能优化,更是现代图像处理软件架构向智能化和高效能转型的体现。
未来随着GPU计算能力的不断增强和编译技术的升级,结合深度学习等先进视觉算法,稳定标签定位方案将更加贴近实际应用场景,助力各类视觉任务实现更准确且高效的标签分布。研究者和开发者们应持续关注GPU并行优化、新兴的Python编译器工具链如Numba的更新,以便在自己的项目中采纳并推动相关技术进步。借助这些前沿手段,传统看似简单但计算密集的图像标注问题得以突破性能限制,发挥出更强的技术生命力。以稳定标签定位算法为例,其从最初纯Python实现到NumPy向量化,再到CuPy尝试,最后通过Numba CUDA内核成功实现硬件级加速,完整展示了现代计算机视觉技术演进过程中软件与硬件协同优化的典范。未来,结合多线程CPU计算和更多GPU核的复合调度策略,有望继续挖掘更深层次的并行潜力,为高分辨率大规模图像分析提供技术支撑。同时,随着人工智能领域图形处理中对实时性和稳定性的不断提升,类似的算法优化技术必将成为推动行业前行的重要力量。
。