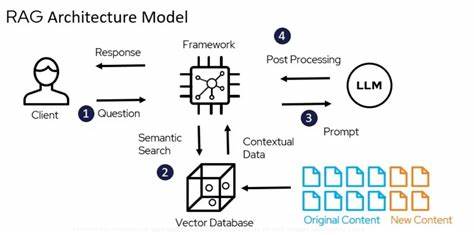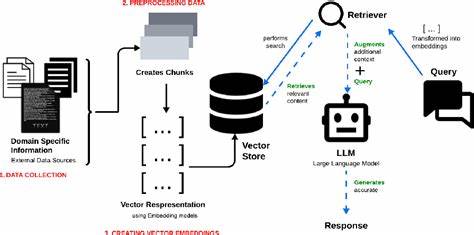
随着人工智能技术的迅猛发展,大型语言模型(LLM)在自然语言处理领域展现出强大的生成能力。然而,纯粹依赖生成模型可能导致信息准确性不足和上下文理解有限的问题。为此,检索增强生成(Retrieval Augmented Generation,简称RAG)架构应运而生,通过结合信息检索机制,有效提升模型输出的透明度、准确性与上下文相关性。近期,一份针对基于PDF文档开发RAG系统的经验报告吸引了广泛关注,为研究者与开发者提供了深入洞见。该报告详细剖析了以PDF文件为主要数据源,构建RAG系统的端到端流程,涵盖数据搜集、文本预处理、索引构建以及最终的响应生成,着重揭示了过程中遇到的各种技术难题及其克服之道。 PDF文件作为信息存储的常见格式,因其结构多样和排版复杂,给文本提取带来了不小挑战。
相比于结构化数据,PDF文档往往包含大量非结构化或半结构化内容,如何高效准确地实现文本抽取成为关键。经验报告中提到,文本预处理不仅包括传统的OCR识别和格式转换,还涉及噪声过滤、分段识别以及表格和图像内容的语义解析。通过多阶段处理流程,系统成功提取出对后续检索任务至关重要的信息块,显著提升了数据质量。 在建立检索索引环节,选用合适的向量化表示技术源自于对文本特点的深刻理解。报告展示了基于语义嵌入的索引策略,结合先进的文本编码器将抽取内容转化为向量空间表示,从而实现高效的相似度搜索。该方法不仅提升了检索精度,也极大地缩短了查询响应时间,为生成模块提供了精准的上下文支持。
此外,针对PDF文档中内容分布不均的问题,采用了分层索引结构,兼顾粗粒度和细粒度检索需要,使得系统在面对复杂查询时表现更加稳健。 生成响应环节则利用了当下主流的生成式大模型。报告特别说明了两种不同的技术路线:一条是借助OpenAI提供的GPT系列API,通过云端强大算力调用高性能LLM实现文本生成;另一条则是基于Llama等开源模型,在本地环境中灵活定制,满足特定应用需求。两者各有优势,OpenAI方案在易用性和性能稳定性上表现突出,而开源方案则提供了更高的控制权和隐私保障。结合检索结果,模型能够生成内容全面且上下文吻合的回答,从而显著提高用户体验和知识推理的可信度。 技术实施层面,该经验报告中的实践细节极具参考价值。
比如在多进程数据处理与异步调用技术的应用中,实现了系统性能的显著提升;在面对不同质量和格式的PDF文件时,引入动态预处理策略,自动适配多样化输入格式;此外,报告还强调了持续迭代和反馈机制的重要性,通过用户交互数据不断优化检索与生成模型的协同能力。这些实践为行业内构建大型RAG系统奠定了坚实基础。 该系统在多个行业场景展示出广泛的应用潜力。尤其在法律、医疗、科研等领域,基于专业文档构建的RAG系统能够快速调取和综合领域知识,辅助决策支持和复杂问题解答。报告指出,随着数据量和模型规模的增长,如何平衡检索效率和生成准确性成为未来发展关键。同时,针对多语言PDF和跨域知识融合等新挑战,也提出了进一步研究方向。
值得注意的是,随着RAG技术的不断成熟,开源与商业化解决方案正展开激烈竞争。报告中开源代码的公开,为社区深化研发提供了极大便利。未来,借助更加智能的文本理解技术、增强的用户交互机制及自动化的知识更新体系,基于PDF的RAG系统将推动生成式AI向更高水平迈进。 总结而言,该经验报告不仅系统介绍了从PDF文档开发RAG架构LLM系统的技术细节和创新实践,更为具体应用场景提供了切实可行的解决方案和优化策略。对于致力于提升生成式AI实际可信度和应用价值的研究者和工程师而言,具有重要的指导意义。随着生成模型与检索技术的进一步融合,基于结构化与非结构化混合知识源的RAG系统必将在智能信息处理领域展现更加广阔的发展前景。
。