随着大型语言模型(Large Language Models,LLM)如OpenAI的ChatGPT和Anthropic的Claude在各类应用中变得愈加普及,如何在确保安全性的前提下高效利用它们成为企业亟需解决的问题。LLM本质上是一种统计概率模型,接受来自用户的非信任输入并生成相应的文本输出。其固有的不可预测性和潜在的误解风险,使得对LLM的权限管理变得尤为关键。企业需要在让模型获取充足数据以完成任务和约束其权限避免意外操作之间取得平衡,这其中的授权机制设计尤为复杂且重要。 在LLM应用中,授权的核心原则是最小权限原则,即LLM在执行任务时应仅获得完成该任务所需的最小权限集合。虽然这一原则在传统IT安全领域已被广泛认可和应用,但在LLM场景下的有效实践尚不普及。
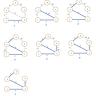
人类用户因具备判断力和责任感往往可被赋予较宽泛的权限,而LLM则依赖于高速连续的计算过程,缺乏反思能力。一旦发生异常或越权行为,其影响可能迅速累积并扩散。因此,设计合理的权限边界对防范潜在风险尤为关键。 授权的复杂度首先体现在LLM如何以用户身份“代理”行动。应用中LLM通常代表具体用户执行操作,这意味着权限集合受限于用户的权限与LLM自身权限的交集,再考虑具体任务的权限需求,从而确定“有效权限”。该模型从三方面形成权限的交织:LLM权能、用户权限与任务权限。
只有当任务权限完全包含于LLM和用户权限的交集内,操作才被允许执行。这样即使模型试图执行超出授权范围的任务,也会被权限边界所限制。 在实际应用中,以GitClub作为示例引入LLM聊天机器人“Bridgit”,体现了授权模型的具体运用。Bridgit支持基于检索增强生成(Retrieval-Augmented Generation,RAG)的数据查询以及代理操作。RAG是一种通过在用户问题中补充相关上下文数据,提升LLM回答质量的技术。这些上下文数据先被转化为向量嵌入(embedding)存入数据库,用户输入也转为嵌入,系统通过相似度搜索挑选相关资料作为辅助信息提供给LLM。
在授权层面,系统必须过滤嵌入对应的原始数据,确保返回的上下文仅包含用户有权访问的部分,防止敏感信息泄漏。 授权实施的合适层级通常为应用层,即在将嵌入映射回源数据时执行权限校验。这样既避免了将授权逻辑委托给LLM的风险,也保证了归属关系、资源类型及权限链条的准确判断。第一方数据的RAG相对简单,因为嵌入与源数据通常同属一个系统,能实现高效一致的权限校验。 然而,当引入第三方数据时,授权问题变得更加棘手。外部系统数据通过API接口接入,嵌入数据储存于本地或专属数据库,源数据与权限信息则存放于第三方平台。
此时授权逻辑呈现“身份与授权逻辑跨越API边界”的局面。为弥合这一鸿沟,有三种主要思路:完全委托第三方授权;同步第三方访问控制列表(ACL)到本地;或者在本地复制第三方的授权规则及其相关元数据。第一种方案实现简单但性能受限,尤其在面对高并发及限流压力时响应时常过长。第二种方案需要第三方系统提供完善的权限API支持,且同步过程复杂且易出错。第三种方案则涉及对外部权限体系的逆向工程与维护,耗时耗力且存在稳定性风险。 在LLM代理(Agent)操作方面,情况类似。
代理通过模型生成指令并调用具体工具(例如分支删除、问题关闭等)完成任务。Anthropic提出的模型上下文协议(Model Context Protocol,MCP)为工具的描述和调用提供了标准化方案,促进多工具集成与动态发现。但授权依然面临边界隔离的问题,需要折中处理用户身份验证与资源级权限校验。OAuth协议虽然在身份验证与基础授权场景发挥巨大作用,然而针对LLM代理操作的细粒度资源权限需求却力不从心。OAuth通常通过访问令牌(token)传递用户角色等静态信息,对变化频繁的资源权限无能为力,导致需要在应用层复写复杂且冗长的授权逻辑。 总体来看,LLM应用中的授权挑战归结为对复杂权限关系的精准建模与执行。
由于LLM利用衍生数据表示与概率计算,安全边界必须放置于源数据与应用逻辑层,避免将授权责任过度依赖于模型本身。针对第一方数据,应在嵌入匹配阶段即过滤权限不符的内容,实现及时且准确的授权校验。针对第三方数据,应权衡授权简易性与系统性能,选择合适的委托或同步策略。对于代理工具调用,推荐借助如MCP等标准协议实现工具描述和权限协调。 最终,遵循“LLM应仅被赋予完成用户请求所需的最小权限”的黄金法则,是保障大型语言模型安全应用的关键。有效权限模型通过结合LLM权限、用户权限与任务需求三者交集,实现权限边界的严谨控制。
虽然理论模型简洁优雅,实际落地却需根据业务架构与数据生态制定策略,兼顾授权复杂度与系统响应效率。当前,企业应注重构建灵活且透明的权限管理框架,借助细粒度授权技术及协议标准,实现对LLM能力的安全释放,推动智能应用稳健发展。