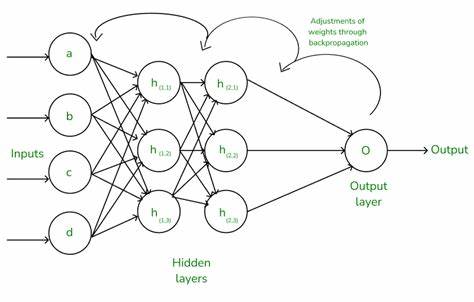
神经网络作为人工智能领域的重要算法,广泛应用于图像识别、语音处理和自然语言理解等诸多领域。在实现其强大预测能力的背后,反向传播算法发挥着至关重要的作用。然而,反向传播常常被繁复的链式法则和复杂的数学符号所包裹,令很多初学者望而却步。实际上,通过一些简单的代数和微积分知识,我们也能逐步揭开反向传播的核心机制,建立清晰的直觉认知。本文将从最基础的数学变化出发,逐步引导读者理解反向传播的本质,而无需深入链式法则的复杂细节。理解反向传播的关键在于掌握微积分中导数的概念。
导数是变量变化率的度量,它告诉我们当输入参数微小变动时,输出结果会发生多大的变化。举个简单例子,假设函数y=x的三次方(y=x³),当x=2时,y等于8。如果我们将x微增0.01,即变成2.01,那么不必重新完整计算y的值,我们可以借助导数来估算y的变化量。y对于x的导数是3x²,代入x=2即可得到12,乘以x的变化量0.01,估算y的变化约为0.12,因此新y值大致是8.12。实际计算(2.01)³=8.120601,误差极小,证明了导数近似评估小幅变化的准确性。由此可以看出,导数是理解反向传播的第一把钥匙。
接下来,我们通过一个最简单的神经网络例子,不含隐藏层,来理解如何用导数修改模型参数。假设输入x为2,权重w为4,目标输出y为10。网络的预测是y^=x×w,即预测值为8。定义代价函数为预测误差Cost=y^−y,即8减10等于-2。代价函数反映了预测结果与目标结果的偏差,值越接近零,说明网络预测越准确。此时,代价为负,意味着预测值小于目标值。
为了减少误差,我们希望调整权重w,但是盲目调整就像在大海捞针,没有指导意义。这里导数再次登场,我们计算代价函数对权重的导数dC/dw。根据这个例子,导数值为输入x,所以dC/dw=2。它告诉我们权重每增加一个单位,代价会增加2个单位。由于当前代价为负,说明需要增加权重,向正确方向移动。于是将w增至5,代价接近零,预测值更加精确。
在有隐藏层的神经网络中,思考过程稍显复杂,但本质依然与单层相同。考虑一个包含输入层、一个隐藏层以及输出层的简单网络。输入x依然是2,两层权重分别是w1=4和w2=3,目标输出为10。预测输出为y^=(x·w1)·w2,等价于2乘以4再乘以3,结果为24。代价则是预测减去目标,即14。接下来计算代价对每个权重的敏感度:对w1的导数为x乘以w2,等于6;对w2的导数为x乘以w1,等于8。
这告诉我们,在当前设置下,权重w2对代价的影响比w1更大。为验证,读者可以尝试增加w1和w2各0.1,然后观察网络输出的变化,便能直观感受到权重对输出的影响差异。在现实中,计算机不会凭直觉调整权重。它们通过不断计算代价函数对每个权重的导数,根据导数大小调整权重值。权重的调整量等于导数乘上一个很小的学习率参数(如0.01),以避免权重变化过大,导致学习过程不稳定甚至发散的问题。这种逐步调整过程反复进行多次,使得权重逐渐逼近最优值,网络预测性能不断提升。
尽管传统教程中反向传播算法常借助链式法则来链式计算各层权重的导数,但通过上述示例我们可以看到,即使不使用链式法则,也能理解每个权重调整的原理。链式法则实际上是将复合函数的导数拆解成多层因素的乘积,对于更复杂网络的计算至关重要,但并非初学理解的拦路虎。综上,真正的反向传播核心是对代价函数进行微分计算,明确每个权重改变时对整体预测误差的影响程度,从而进行有指导的参数调节。对导数本质的深入理解,有助于学习者建立正确的数学模型认知,突破神经网络黑盒的神秘感。通过实践手动计算简单网络的导数和权重调整,不仅能激发学习兴趣,也为后续深入学术和工程应用打下坚实基础。未来,随着不断堆叠隐藏层和引入非线性激活函数,计算过程会复杂许多,但反向传播调整参数的核心思想依然不变。
理解了简单网络的反向传播,便跨过了神经网络学习的最难一环。科学家和工程师正是在这一基本原理指导下,设计了各种高效的深度学习模型,解决了计算机视觉、语音识别和自动驾驶等关键问题。理解反向传播,不仅是迈向成为机器学习专家的第一步,也是拥抱智能时代的必备知识。鼓励读者动手计算,循环实验,相信每个人都能理解并掌握这门强大的技术,从容应对更复杂的深度学习挑战。









