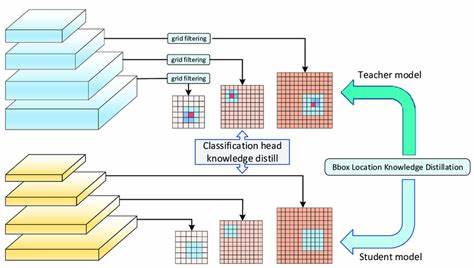
随着人工智能技术的不断进步,深度学习模型的规模与复杂性也在迅速增长。大型模型如数以十亿甚至万亿计参数的语言模型和视觉语言模型虽然具备强大的能力,但其庞大的计算资源需求和高昂的部署成本使得企业在实际生产环境中面临诸多挑战。模型蒸馏,作为一种将大型复杂模型(教师模型)知识迁移到更小巧高效模型(学生模型)的技术,正成为优化AI部署的关键手段。它不仅能够在降低计算消耗和响应延迟的同时,尽可能保留原模型的性能,还为边缘设备和实时应用场景带来了切实可行的解决方案。本文将详细探讨何时应在生产中采用模型蒸馏,并通过实用视角揭示其优势和注意事项,以助力企业在AI创新中实现性能与成本的平衡。 模型蒸馏的核心价值在于通过教师模型的输出指导学生模型学习,实现小模型在效能上的最大提升。
在生产环境中,首先需关注模型蒸馏在降低高昂计算成本方面的优势。当前大型模型往往需要极为庞大的显存及算力支持,例如拥有70亿参数的模型可能需要168GB的GPU内存,这在云端运行时引发巨额费用。通过蒸馏后的模型体积大幅缩减,能有效减少资源占用和运行成本,使得人工智能应用在企业层面具备更好的经济效益和可扩展性。 除了成本因素,模型蒸馏在提升系统响应速度和用户体验方面的价值也尤为突出。许多实际应用,如智能客服、推荐系统和实时分类器,均对响应延时有严格要求。运行大型模型时,生成一次响应可能耗时数秒甚至数十秒,这会极大影响用户满意度。
例如,某视觉语言模型在对图像进行分类和元数据提取时,延时长达25秒,显然难以支撑消费级应用需求。经过蒸馏的紧凑模型能够显著缩短预测时间,提升交互体验的连贯性和流畅度,从而助力应用在市场竞争中脱颖而出。 资源受限环境也对模型蒸馏提出了迫切需求。智能手机、物联网设备、嵌入式系统等硬件平台往往受限于内存、算力和功耗限制,无法运行大型AI模型。通过模型蒸馏,企业能将复杂模型的能力压缩到适配这些平台的规模,实现先进功能的本地部署,减少对云端的依赖,提高数据隐私安全性和实时性。例如,通过蒸馏模型,小型设备能够具备人脸识别、图像分类等功能,在边缘计算领域创造更广阔的应用前景。
复杂多模态任务中,模型蒸馏同样展现出独特价值。视觉与语言信息的结合使任务更加复杂,对于传统单一模态的模型难以胜任。视觉语言模型虽性能卓越,但体量庞大。将这类模型蒸馏成针对特定任务的小模型,有助于企业在保证性能的基础上实现轻量化部署。且蒸馏过程可聚焦于狭义任务,避免全能模型上的冗余复杂性,使得模型更专注于业务需求,提升实用性和效率。例如,医疗图像诊断中的报告生成或植物种类识别,通过蒸馏技术能够提供实时且有效的解决方案。
此外,模型蒸馏为传统模型难以达到的精度水平提供了突破口。简单模型在某些复杂任务中表现不佳,但大型模型却具备强大处理能力。蒸馏技术能够将大型模型的知识有效迁移给小模型,让小模型获得类似的预测能力,同时大幅降低计算和存储资源消耗,这对于成本敏感的企业尤为关键。 构建高质量的蒸馏数据集是确保蒸馏成功的基石。首先需要明确任务定义,并设计详细且富有指导性的提示语,确保教师模型输出稳定且具有代表性。数据采集应涵盖多样化输入,涵盖各种可能出现的场景和边缘情况,以提升学生模型的鲁棒性。
采集方式包括实时收集用户输入与教师模型产生的输出,结合实际业务场景,确保数据的相关性和实用性。生成的教师模型输出需严密验证,尤其是在专门领域如医疗诊断中,可以邀请专家对部分数据进行标注和审核,防止错误信息影响学生模型性能。此外,合理的数据平衡和增强能提升模型的泛化能力,保证不同类别数据均衡分布并覆盖复杂变化。为了防止过拟合,划分专门的验证集也非常重要,使得训练过程中的模型调优更具针对性。蒸馏所需的数据量依赖于任务复杂度,视觉语言类任务通常需要数千乃至数百万对输入输出样本,充分体现蒸馏数据的多样性与规模。 需要强调的是,模型蒸馏并非万能灵药,它作为提升延迟和成本效率的重要工具,是在大模型已有能力基础上的优化方案。
企业应视业务需求合理选择,初期可通过部署大模型获取业务数据,逐步通过蒸馏实现模型轻量化和快速响应。训练蒸馏模型仍需一定投入,训练成本因模型大小与数据量差异较大,建议结合企业实际资源和性能需求做好规划。 综上所述,模型蒸馏技术在生产环境中的应用,主要针对成本高昂、响应延迟、资源限制及复杂多模任务等关键痛点,帮助企业实现高效且低成本的AI应用部署。未来,随着模型架构和蒸馏技术不断演进,模型蒸馏有望成为人工智能普及与产业升级的重要推动力。企业应紧抓这一趋势,结合实际应用场景设计合适的蒸馏策略,打造兼顾性能与效率的智能产品,助力业务持续稳健发展。