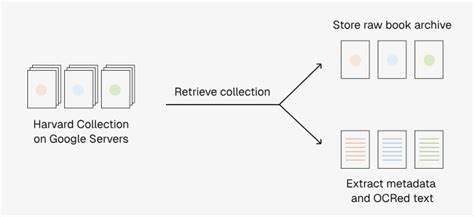
近年来,随着人工智能特别是大语言模型技术的飞速发展,数据资源的重要性日益凸显。优质且丰富的训练数据是提升模型理解力与生成能力的关键。然而高质量公开数据集的匮乏成为业界瓶颈。针对这一难题,哈佛大学图书馆携手多方力量推出了规模空前的Institutional Books 1.0数据集,旨在为学术界与工业界提供一个内容丰富、质量精良且具备全面文献信息溯源的数据资源。Institutional Books数据集囊括了接近百万册属于公共领域的历史图书,总计约2420亿字,其中囊括超过250种语言。这些图书大部分最初由哈佛图书馆参与的谷歌图书项目于2006年开始数字化。
通过细致的文本识别(OCR)与后期处理,项目团队不仅提取出文本数据,还整合了详尽的书目元数据,确保用户能够清晰追溯文献来源。巨大规模的数据意味着Institutional Books具有广泛的应用前景。对于自然语言处理领域,这一数据集可以作为训练大语言模型的重要补充,尤其能够加强模型对多语言和历史文本的理解能力。由于文本基于公共领域著作,开放获取的特点使得科研、教育、艺术和文化机构能够合法利用,从而极大地促进了数据共享与合作研究的可能。此外,丰富的元数据赋予研究者对文本维度的多重视角,例如作者背景、出版年代、地域分布等信息,为数字人文领域提供了跨学科研究的基础。历史学家、语言学家和社会科学研究人员可以基于该数据集进行数据驱动的历史文献分析,解码文化发展与语言演变的轨迹。
数据集还特别关注文本质量的提升,不仅保留了OCR原始文本,还提供经过后期校正的版本,方便不同需求的用户选择和使用。项目团队对数据的准确性及其可读性进行了系统测评,确保数据适合机器学习与人工阅读的多样化场景。哈佛图书馆的Institutional Books计划秉持可持续发展理念,构建了清晰、透明的数据溯源链,倡导负责任的数据治理。这种开放且规范的管理模式为未来更多公共文化遗产数字内容的共享树立了典范。同时,通过与学术界、工业界以及社会公众的积极互动,把历史文献数字化成果转化为推动学术创新与公众教育的重要力量。从技术角度看,该项目综合运用了先进的自然语言处理技术、数据管理系统及云计算资源,确保庞大数据能高效存储、访问和利用。
机构间合作促进了数字人文与人工智能领域的跨界交流,加速了知识提取与内容再创造的步伐。哈佛Institutional Books的开放也激励了全球更多文化机构挖掘并数字化自身宝贵文献资源,以实现共建共享的数字文化生态。作为一个典型的示范项目,Institutional Books不仅满足了大规模语言模型训练的需求,也促进了历史文化研究和数字公共服务的融合发展。未来,随着更多数据的整理与注释完善,Institutional Books有望成为全球最大的历史文献数字库之一,丰富人类知识的传承与创新。总而言之,哈佛图书馆Institutional Books 1.0数据集以其庞大规模、多语种覆盖和高质量文本,为人工智能和数字人文研究开辟了崭新天地。它不仅彰显了文化遗产数字化的重要性,更体现了开放数据推动学术进步和社会共享的巨大潜力。
随着该数据集的进一步推广,预计将在全球范围内激发强烈的科研热潮,助力推动语言模型技术迈上新台阶,也为历史文献的数字保护和利用树立了全新范例。未来,Institutional Books无疑将成为数字时代连接过去与未来的重要桥梁,助力知识的广泛传播与创新发展。