随着人工智能、大数据和科学计算的迅猛发展,GPU作为高性能计算的核心硬件设备,越来越受到程序员和研究者的关注。在GPU编程领域,如何在性能和灵活性之间取得最佳平衡一直是技术发展的关键。Gluon作为一种基于与Triton相同编译器栈的新兴GPU编程语言,正是在这一背景下引起广泛关注。本文将全方位解析Gluon语言的设计理念、核心特性和应用实践,帮助开发者深刻理解其在GPU编程领域的价值。Gluon的出现并非偶然,而是基于对现有GPU编程模型的深刻反思和优化。它继承了Triton强大的编译器基础,但在语言层面进行了重新设计,使开发者能在GPU内核编程时获得更细粒度的控制权。
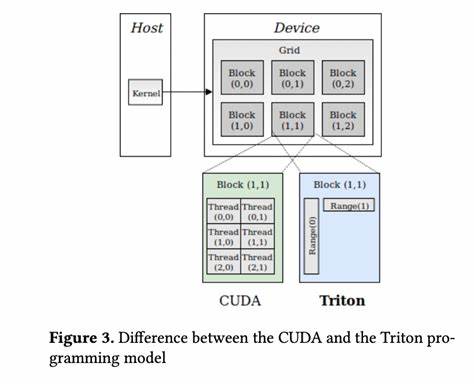
这种设计理念的转变,使得Gluon不仅能够满足复杂计算需求,还能通过手写底层细节优化打破传统高阶抽象带来的性能瓶颈。理解这一点,对于想要最大化利用GPU硬件潜力的开发者来说至关重要。从编程模型来看,Gluon延续并深化了基于tile(块)分布的单程序多数据(SPMD)思想。诸如Triton这类语言通常抽象出许多底层细节,让程序员专注于算法逻辑,减少GPU复杂硬件的干扰。但这也限制了对内存布局、线程调度等关键因素的手动调优。Gluon则打破这一限制,允许开发者直接操作和管理内存分配、数据移动和异步执行策略,从而能针对具体硬件架构量身定制优化方案。
在实际开发中,Gluon提供了类似Python的DSL(领域专用语言)接口,兼具易用性和底层性能。开发者可以通过修饰器方式定义内核函数,直接操作指针和内存地址,完成高效的数据加载和存储。内核的启动也采用类似Triton的host端调用方式与PyTorch集成,支持灵活的网格大小和线程块配置。这种设计既保留了高级语言的开发体验,也让GPU内核发挥了极限性能。为什么性能优化在Gluon中如此重要?因为GPU计算的瓶颈往往不在算法本身,而是计算资源的利用率和内存访问效率。当前许多GPU编程抽象将底层内存控制交由编译器处理,虽然便利却可能错失硬件特性带来的性能提升。
Gluon正是通过显式让用户掌控这些细节,实现了对内存访问模式、线程协作和指令级调度的深度优化。举例来说,Gluon支持用户为内核指定constexpr参数,配置精细的线程块尺寸和循环拆分方式,并在程序中显式管理数据布局。这种精细化控制能够极大减少内存访问冲突,提升带宽利用率,显著提升大规模矩阵乘法等核心操作的计算速度。此外,Gluon还内置了自动调优机制。用户可通过配置搜索不同超参数组合,在程序运行时自动选择最优方案。结合手动优化的灵活性,自动调优帮助开发者快速锁定性能瓶颈,实现实用与极致性能的平衡。
从生态系统看,Gluon依托Triton成熟的编译器框架,天然兼容现代深度学习框架如PyTorch。这意味着GPU计算资源管理、数据转换和内核调度都能高效无缝集成到现有工作流中,降低了学习成本和迁移难度。此优势使Gluon成为科研和产业界探索GPU领域底层优化的重要工具之一。展望未来,Gluon代表了一种融合灵活设计和极致性能追求的GPU编程趋势。随着GPU架构不断迭代,编译器技术和语言设计也将持续演进。Gluon在为开发者提供低级别控制的同时,不断完善抽象和自动化支持,使得GPU程序的开发、维护和性能提升更加高效。
这对人工智能模型加速、高性能科学计算及图形渲染等应用场景均具有深远影响。总而言之,Gluon作为基于Triton编译器栈的新型GPU编程语言,精准回应了当前GPU程序设计的痛点和挑战。通过暴露底层细节,赋予开发者极大自主权,配合自动调优等现代技术,极大提升了GPU内核的性能潜力。掌握Gluon技术不仅能带来性能提升,更能加深对GPU计算细节的理解,为各类高性能计算任务注入新动力。对于GPU开发者而言,深入学习和实践Gluon将是一条提升技术高度、拓展开发视野的不二之路。 。