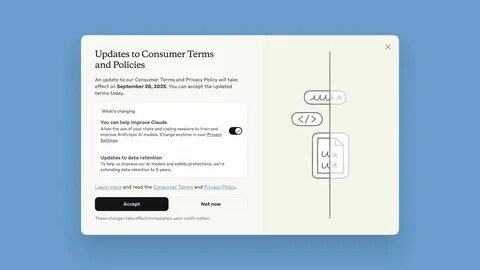
Anthropic 宣布开始将用户与 Claude 聊天机器人的新对话用于训练其大型语言模型,引发了关于隐私、数据使用和监管合规的广泛关注。生产级 AI 模型需要大量真实对话来提升理解能力和生成质量,但当聊天记录包含敏感个人信息或商业机密时,训练数据的再利用就可能带来风险。了解 Anthropic 的做法、掌握可行的退出途径以及建立稳健的数据治理机制,对个人用户和企业客户都至关重要。 首先,需要明确公司声明的核心要点:Anthropic 计划将新产生的 Claude 聊天记录作为训练数据来源之一,除非用户明确选择退出。这意味着默认情况下,用户与 Claude 的对话可能被用于改进模型的语义理解、生成能力和对话策略。模型训练通常涉及对话清洗、去重、标签化与微调,训练过程可能保留可用于模型参数更新的文本特征。
虽然这种做法能提升产品质量和响应准确性,但也带来了数据主权和隐私保护的挑战。 了解如何选择退出是第一步。对于个人用户,优先检查账户的隐私与数据设置,寻找与训练数据或数据使用相关的选项。常见的做法是在账户设置或隐私面板中提供"禁止将我的对话用于模型训练"之类的开关。如果找不到明确选项,可以通过安全或隐私页面查找帮助文档或常见问题解答。另一条常见路径是联系客户支持以书面形式提出数据使用限制请求,保存通信记录以便日后核查。
企业客户应当采取更严谨的合同与技术控制措施。企业版或付费订阅通常会有不同的数据保留政策与更强的隐私保护承诺,购买前应确认服务条款中是否包含"不得将企业数据用于通用模型训练"或"仅可用于服务改进并按合同限制使用"等条款。对接 API 时,检查是否提供针对训练数据的 opt-out 标识或请求头,或是否存在数据不保留(data retention off)和不用于训练的参数。必要时,应在合同中加入数据处理协议(DPA)、保密协议(NDA)与责任条款,以建立法律上的数据隔离与追责路径。 若希望彻底清理历史对话,用户应熟悉账户中删除与导出数据的流程。导出数据有助于备份重要信息,而删除历史对话可以减少未来被用于训练的文字样本。
注意许多平台的删除操作并不一定立即从备份或长期存储中彻底清除,因而应询问数据删除的时效与范围,以及是否覆盖备份与日志。合规要求下,像 GDPR 的"被遗忘权"可以作为申请删除的法律依据,但执行细节仍需与平台沟通确认。 在保护数据时采取的具体策略包括限制敏感信息在对话中的出现,例如避免在聊天中粘贴身份证号码、医疗记录、公司机密、未公开的财务数据或受保护的个人信息。对于必须在对话中处理敏感数据的场景,建议使用企业内部部署的私有实例或选择明确提供"零训练"条款的商业产品。此外,使用端到端加密或在传输层采用强加密协议可以降低被拦截的风险,但对话一旦进入平台后端仍可能被用于模型训练,因此技术加密并不能完全替代使用条款与合同保护。 从监管角度看,数据保护法律对"用于训练 AI 模型"的行为提出了更高的透明度与合规性要求。
欧盟的 GDPR 强调数据处理的合法依据、最小化原则、可解释性以及用户权利;加州消费者隐私法(CCPA/CPRA)则关注数据使用与销售的告知与选择权。企业在使用 Claude 或任何类似服务时需要进行数据保护影响评估(DPIA),评估模型训练对个人隐私的潜在影响并制定缓解措施。透明的隐私政策、明确的同意流程与清晰的 opt-out 机制将有助于降低合规风险。 对比其他主要供应商的做法,有些公司在默认设置上已经区分了免费用户与付费用户的数据使用权。付费或企业用户往往能获得不将数据用于训练的承诺或可选的私有化部署。消费者在选择 AI 聊天产品时应将"是否将对话用于训练"作为重要决策因素之一。
如果产品未提供清晰的退出方式或企业政策没有保障,敏感对话最好避免在该平台上发生。 从技术和伦理角度评估,使用真实对话训练模型确有合理性。真实用户对话能帮助模型适应自然语言的多样性、纠正偏差和改善交互体验。然而,训练数据往往不会完全匿名化,文本中包含的具体细节可能通过模型参数间接保留,引发模型记忆泄露或被用于不当生成。因此,研究与工程团队应在数据预处理阶段强化去标识化、差分隐私等技术手段,减少模型记忆原始个人信息的风险。 面对 Anthropic 的新政策,用户可采取多重防护措施。
首先,定期检查并更新隐私设置,主动选择退出训练数据使用。其次,使用付费或企业版本以换取更严格的数据保留和训练约束,或通过合同条款达成对数据用途的明确限制。再次,避免在对话中分享敏感信息,必要时通过脱敏、摘要或替代表达来传递必要信息。对于开发者和 IT 管理者,审查 API 文档与服务协议,使用可配置的数据保留参数,或部署私有托管解决方案来保持数据控制权。 尽管个人和企业可以采取上述措施,长期解决方案仍需行业和监管层面的改进。平台运营者应提高透明度,主动披露训练数据来源、去标识化方法和数据保留期限。
监管机构可以制定针对 AI 训练数据的最低合规要求,明确什么类型的数据绝对禁止用于训练,何种情形需要强制同意或更高程度的保护。行业内独立的审计与第三方合规认证也有助于建立信任,例如通过隐私影响评估公开报告或接受外部安全评估。 最后,用户在与 Claude 或其他聊天机器人交互时,应保持理性权衡。当模型改进和服务创新需要数据时,平台的改进也可能直接提升个人使用体验。选择是否允许数据用于训练应基于对隐私风险的理解、对平台信任度的评估以及对潜在收益的权衡。如果选择退出,务必按照平台指引完成相关设置与书面确认,保存沟通记录以便在出现争议时作为证据。
Anthropic 将 Claude 聊天记录用于训练是行业内关于数据再利用问题的最新案例。对个人用户而言,重点是主动管理隐私设置、避免在对话中泄露敏感信息并寻求明确的退出流程。对企业而言,重点是通过合同与技术手段确保数据隔离、采用企业版或私有部署和进行必要的合规评估。对整个行业而言,需推动更透明、更可控、更合规的数据使用方式,以在推动 AI 进步的同时保护用户的基本隐私权和数据主权。 。