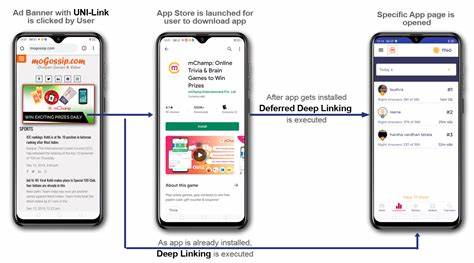
随着人工智能技术的迅猛发展,尤其是大型语言模型(LLM)的普及,围绕AI安全的讨论愈加热烈。人们在探讨如何管控和评估这些模型时,常常陷入一个容易被忽视但极其关键的问题:我们究竟应该如何衡量模型的表现?是依据模型“意图”还是实际产生的“影响”作为标准?事实上,传统的模型解释和安全评估多集中于理解模型做出某项决定背后的意图,但在现实应用中,更为重要的是识别模型行为对环境和用户的具体影响。本文将深入解析这一AI安全领域的核心难题,介绍一种名为“Landed Writes”的创新方法,系统阐明其理论基础、关键发现及未来应用前景,助力研究者和开发者更精准地掌握和控制AI系统的实际表现。 大型语言模型的神秘之处在于其内部运算机制的复杂和不可预知性。很多人误以为这些模型是由一系列明确且可解释的逻辑规则驱动,实际上,它们依赖于数以万亿计的参数、庞大的神经网络架构以及复杂的激活模式,在输入一个简单提示如“2+2=”时,模型通过数以亿计的内部状态变换和激活最终产生输出“4”。这种运算过程极难从传统语义或逻辑层面加以解析,更别说完整理解其决策链条的每个环节。
当前主流的模型解释框架通常忽视了一个关键环节——归一化(Normalization)过程对内部信号的影響。在许多变换器模型结构中,来自不同神经单元(神经元)和注意力头的输出先被加权叠加产生残差流(Residual Stream),但此时的信号会经历Root-Mean-Square(RMS)归一化处理以及对应的缩放系数,这一过程会极大地放大或压缩不同层级的信号影响。具体而言,模型不同层级的缩放系数差异巨大,早期层输出信号可能被放大近百倍,而后期层输出则可能被压缩甚至保持不变。这种系统性的缩放效应对于最终模型的预测结果具有决定性影响,却往往被现有的解释工具忽略。 “Landed Writes”方法正是基于关注归一化后实际“落地”的信号贡献而提出。它突破传统只关注神经单元“试图写入”数值大小的做法,转而追踪经过归一化放大或缩小后的真实贡献,精确量化每个头或神经元对模型输出残差流的实际影响。
换句话说,这种方法直接衡量了模型内部各计算单元“写入”至残差空间的最终数值,而这些数值才是决定模型下一步预测的真正依据。 采用“Landed Writes”分析的大型语言模型表明,它们在预测下一词时的决策高度稀疏,实际主要依赖少数几个关键坐标的贡献,这些关键坐标往往被早期层显著放大。同时,这些坐标的归一化缩放因子在不同提示输入中表现出惊人的稳定性,说明模型内部存在着持久且一致的信息处理机制。这一发现不仅赋予了我们针对模型内部行为的更精准观察视角,也为后续的安全评估和解释策略提供了切实可行的技术基础。 为什么单纯关注神经单元“意图”分析存在局限?举例来说,在没有考虑归一化放缩过程时,某些单元的微小写入可能被误判为无关紧要,但经过放大后却成为决定性因素。反之,某些原本看似关键的写入在归一化后贡献极小,这种落差说明了单靠未归一化数据难以理解模型真实的工作机制。
这正如我们在日常沟通中,不仅要关注说话者的意图,更要重视听者最终接收到的信息内容,二者的差异决定了沟通的成效和意义。 落地写入的追踪实施相对经济且高效。通过在模型前向传递时添加特定钩子函数,捕获各层的归一化参数和写入数据,研究者能实现对“落地写入”的实时监控和分析,无需额外复杂的梯度跟踪或训练。这种轻量级监测策略适合快速诊断模型行为,识别潜在风险点,同时也有助于改进模型架构设计,优化不同组件的贡献分布。 当然,这一方法并非万能。“Landed Writes”仅提供了模型行为的表面映射,具备因果盲区,不能直接揭示神经元为何做出某种写入,更无法独立解构复杂的层间竞争与合作机制。
它属于首阶分析工具,需要与因果推断、脱嵌(disentanglement)和特征自编码器(SAE)等先进方法结合使用,才能深度揭示模型内部计算动力和决策逻辑。 未来,围绕“Landed Writes”的研究有着广泛发展潜力。无论是在AI安全性检测、模型压缩、推理效率提升还是新型解释框架构建中,它都能成为关键技术节点。探索如何利用落地写入构建更精细的因果图谱、识别模型的“关键算子”和“原子操作”,将为科学理解和控制AI模型带来突破。与此同时,开放源代码实现和整合至主流框架如HuggingFace Transformers中,也将在社区推动下加速落地应用。 综合来看,解决AI安全难题的核心之一是精准测量模型行为的“影响”而非简单推断“意图”。
落地写入为此提供了技术路径,有效揭示模型内部如何从神经元级别汇聚信号,塑造输出决策。随着AI应用场景日益多样化,提升对模型预测机制的透明度和可控性,精准评估每一次输出的实际影响势必成为保障安全和信任的基础。我们正站在人工智能解释和安全研究新的转折点,借助深刻的理论洞察与实践工具,迈向更加安全、可靠的智能未来。