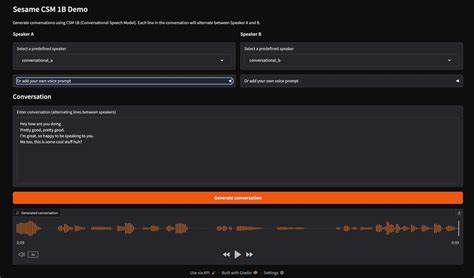
随着人工智能技术的迅猛发展,大型语言模型(LLMs)在自然语言处理领域扮演着核心角色。如何更高效地利用多种语言模型资源并满足不同用户的个性化需求,成为当前研究和应用中的重要课题。模型字面量(model-literals)、模型别名(model-aliases)以及偏好对齐路由(preference-aligned routing)作为提升语言模型管理和调用效率的关键技术,正逐步引起业界和学术界的关注。本文将深入探讨这些技术的定义、应用场景及其对未来大型语言模型发展的潜在影响。大型语言模型因其参数庞大和训练复杂,通常存在调用成本高、响应速度慢以及定制化能力不足等问题。模型字面量概念的引入,旨在通过对模型标识的具体描述,明确和规范模型的调用规则。
例如,模型字面量可以直接指出所需模型的版本、类型或特定能力,确保调用时精准无误。相比传统的通用调用方式,模型字面量提供了更细粒度的控制,帮助开发者和系统快速识别目标模型,优化资源分配和调度机制。模型别名则是在模型字面量的基础上进行的抽象和封装。通过为特定模型或模型组合赋予简洁且易记的名称,简化调用流程,同时支持模型的替换和升级。模型别名赋予系统更高的灵活性,便于根据实际需求切换不同的模型实例,无需修改调用逻辑,有效降低维护难度并提升系统的扩展性。这种技术对于需要频繁更新模型参数或测试不同模型效果的场景尤为重要。
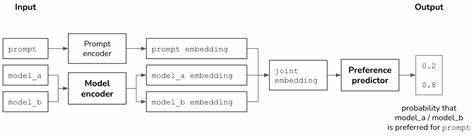
偏好对齐路由技术是一个更加智能的调度机制,它通过分析用户或应用端的偏好,实现模型请求的智能路由,从而保证输出内容更贴合用户需求。基于模型字面量与别名,偏好对齐路由能够动态调整模型调用策略,比如优先使用更擅长特定任务的模型,或依据不同用户的风格喜好,调用相应的模型版本。这不仅提升了用户体验,也有效降低了计算资源的无效消耗。在实际应用中,这些技术结合使用能够显著提升多模型环境下的大型语言模型系统效率。模型字面量和别名允许系统快速识别和替换目标模型,偏好对齐路由则确保请求能够匹配最适合的模型实例,实现个性化又高效的交互。譬如,某个客户服务平台通过整合多种语言模型,可以依据客户的语言偏好和问题类型,智能选择响应模型,提升回答的相关性和准确率。
技术落地过程中仍面临诸多挑战,包括模型标识的标准化机制、别名管理的版本控制以及路由算法的复杂度等。研究者们需设计合理的模型描述体系,确保模型字面量的唯一性和一致性,同时构建高效的别名映射及其更新策略。此外,偏好对齐路由涉及多维度用户数据和实时模型性能指标,如何平衡隐私保护与路由精准性,是实现该技术的关键难点。展望未来,模型字面量、模型别名与偏好对齐路由将成为LLM生态系统的基础设施部分,促进多模型协同和混合调度平台的诞生。随着模型种类和版本持续增多,系统对模型管理的灵活性和智能化需求愈发迫切,这些技术有望为构建更具扩展性和响应性的语言智能服务打下坚实基础。同时,结合联邦学习、多任务学习等新兴技术,将进一步完善个性化模型调度机制,实现真正意义上的个性化智能交互。
总结来看,模型字面量、模型别名和偏好对齐路由代表了大型语言模型领域的一次重要技术进步。它们通过规范化模型调用、简化管理流程和智能匹配用户需求,大幅提升了语言模型的实用性和效率。未来,无论是在商业化应用还是科研探索中,合理利用并推动这些技术的发展,将对推动人工智能落地和普及产生深远影响。随着相关研究不断深入,期待更完善的标准与工具问世,助力构建更加智能化、多元化的语言模型生态,满足不同场景下用户对智能交互的多样化需求。 。