人体由成千上万亿个细胞组成,每个细胞虽几乎拥有相同的基因组,但其表现出的功能和状态却千差万别。免疫细胞通过调控炎症反应抵抗感染,干细胞可分化成不同的组织类型,而癌细胞则能逃避正常的调节信号,实现失控增长。细胞的这些特性并非仅仅取决于DNA序列本身,而更多地源自基因表达模式的差异。换句话说,细胞之所以不同,是因为基因在时间和空间上的“开关”控制,进而导致RNA表达模式的变化。RNA分子是基因表达的直接产物,反映了细胞内活跃基因的状态。通过深入研究和预测细胞内RNA的表达动态,科学家们可以洞察细胞在健康、炎症乃至癌变过程中的状态变化。
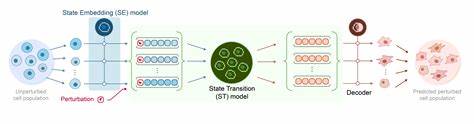
正是在此背景下,Arc研究院推出了首个名为State的虚拟细胞模型,标志着细胞生物学和人工智能结合的重大进展。State模型能够基于初始转录组数据和外界干扰因素,预测细胞内RNA表达的变化趋势,从而揭示细胞在不同条件下的转变路径。Arc研究院聚合了来自近1.7亿个单细胞及1亿多个外界扰动数据,涵盖70个人类细胞系,利用前沿AI技术进行模型训练,使State在预测准确性和适用范围上均达到业内领先水平。State模型由两个互相配合的模块组成,分别是状态嵌入(State Embedding,SE)模型和状态转变(State Transition,ST)模型。SE模型通过将高噪声、高维度的转录组数据转换到一个更平滑、更易处理的多维向量空间,有效降低技术误差的干扰,并使得同类细胞在该空间自动聚类。ST模型则采用双向变换器架构,利用自注意力机制处理细胞集合的复杂异质性,灵活捕捉细胞周期、测序偏差等多种生物技术背景因素,准确预测细胞状态在不同扰动环境下的迁移轨迹。
值得一提的是,State模型在多项标准测试数据集上的表现超越了现有先进模型,提升了50%的扰动效应区分能力,且在真正的差异表达基因识别准确性上实现了两倍的提升。更重要的是,它首次稳定超越了简单线性模型的基准,充分展现了深度学习技术在生物细胞多样性模拟中的潜力。为何强调使用扰动数据进行训练?单纯的观察性RNA测序数据固然庞大,但因缺乏明确的因果关系,难以准确揭示基因间的直接作用机制。通过CRISPR等基因编辑工具制造特定基因的敲除或激活扰动,实验产生的扰动数据能直接捕获基因功能之间的因果关系,极大地提高了模型预测的生物学可信度和有效性。Arc研究院利用自主研发的scBaseCount系统采集统一处理单细胞数据,以最小化实验和分析偏差,保证了数据的高质量和整合性。State模型本身也对这些潜在的技术和生物异质性进行了建模,使得来自不同实验室的数据能无缝合并使用。
虽然目前State仍处于首个版本,Arc研究院的团队已明确表达持续迭代、提升模型能力的愿景。基于生物学领域逐渐明朗的规模效应,随着训练数据量的不断扩大,State及其未来版本的准确率和适用性将显著提高。Arc此前在DNA序列语言模型上揭示的规模规律,也为这一进步奠定了理论基础。State的问世不仅为基础科学研究带来便利,更展现了未来医药领域的巨大潜力。类似于蛋白质折叠模型AlphaFold在蛋白质结构预测和药物设计上的应用突破,State可以帮助科学家提前在虚拟环境中模拟细胞对药物或基因扰动的反应,从而加速新药物的筛选和验证过程。这一点对于提高临床试验的成功率尤为关键,因为目前约90%的新药因疗效不足或副作用被迫放弃。
未来,研究人员能够利用State模拟数百万种基因和药物组合的干预效果,大幅缩小实验范围,优化资源配置,推动个性化医疗和精准治疗。与此同时,Arc研究院还推出了Cell_Eval评价系统,针对虚拟细胞模型提出了一整套新型评估指标,涵盖差异表达预测和扰动强度估计,进一步促进模型性能的透明化和科学社区的标准化比较。Arc研究院希望全球生物学家能积极利用State模型,将其整合到实验设计和数据分析中,不断反馈和推动模型的迭代升级。虚拟细胞模型State的成功开发,无疑是人工智能助力生命科学的里程碑,预示着通过计算手段深入理解生命过程、加速医学创新的新时代已经到来。未来随着技术完善及数据积累,虚拟细胞模型将成为科学家不可或缺的工具,为攻克癌症、免疫疾病及多种复杂病理提供强大助力,开创生物医学研究和临床应用的新局面。Arc研究院坚持融合先进的机器学习方法与实验生物学优势,打造了这款具有划时代意义的虚拟细胞模型。
State.model是连接现实实验与计算模拟的桥梁,也代表了科研团队对未来精准医疗无限可能的期待。随着科学界对细胞复杂性的理解不断深化,虚拟细胞模型有望促成更多创新方案的诞生,推动人类对生命本质的认知迈上新台阶。