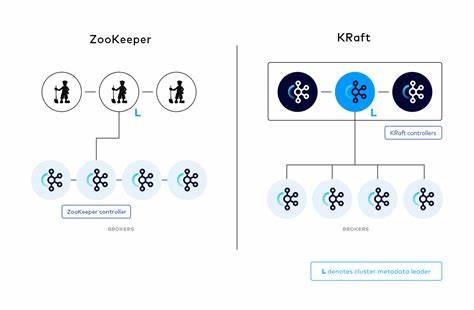
Apache Kafka作为分布式消息队列领域的领先者,随着生态的不断演进,迎来了重大的架构更新。其中最为核心的转变莫过于Kafka逐步弃用传统的ZooKeeper组件,转而引入了KRaft(Kafka Raft)协议,打造出全新的无ZooKeeper架构体系。Kafka KRaft不仅简化了系统部署和运维复杂度,还极大提升了元数据管理的效率和一致性。深入理解Kafka KRaft架构及其内部通信机制,对于架设高可用、高性能的Kafka集群尤为关键。Kafka KRaft架构的基础在于构建一组称为KRaft控制器的节点,这些控制器组成一个Raft协议的共识组。Raft共识算法通过动态选举机制,挑选出唯一的领导者负责集群元数据的维护和分发。
领导者同时保证数据同步和一致性,其他控制器作为跟随者被动接收最新的元数据状态。当领导者节点发生故障时,跟随者节点通过Raft协议快速协商选举出新的领导者,确保元数据层始终保持高可用和强一致性。Kafka KRaft将传统的ZooKeeper角色划分进行改造,集群中的服务分为控制器和Broker两类角色。控制器节点专注于集群元数据的管理、协调分区领导权以及对Broker的状态监测。而Broker节点则聚焦于数据的生产、消费和存储,处理前端客户端请求。虽然技术上允许一个节点同时承担控制器和Broker职责,不过在生产环境中为了保证性能隔离和容灾,通常建议将二者分开部署。
KRaft架构对控制器之间的交互采用基于拉取(pull-based)的通信方式,区别于ZooKeeper的推送机制。领导者控制器维护着最新的元数据日志,跟随者控制器会定期向领导者发送FETCH请求,从而拉取并同步最新的元数据信息。这一设计充分体现Raft协议“跟随者主动获取数据”的核心思想,增强了系统对一致性和故障恢复的保障。Broker节点则仅与当前的领先控制器进行交互,避免了多控制器环节引发的复杂通信。Broker负责主动向控制器领导节点发起心跳(heartbeat)请求,用于报告其存活状态,同时定期发起元数据的FETCH请求以获取集群最新配置信息。此外,当需要执行诸如主题创建、分区调整等管理操作时,Broker也会将这些请求转发至控制器领导者,由控制器统一处理并推动变更传播。
这种单一领导者集中式管理的架构,既保证了元数据状态的一致性,也简化了Broker端接入逻辑。数据层面,Kafka Broker之间依然采用传统的基于拉取型的分区数据复制方式。副本Broker主动向主副本Broker拉取消息数据,保证消息的高可用性和冗余备份。此复制机制与控制器间的元数据同步形成了呼应,共同提升Kafka整体的稳定性以及故障恢复速度。从实践角度出发,配置Kafka KRaft集群时通常会结合容器编排工具如Docker Compose,分别启动独立的控制器节点和Broker节点。控制器通过Raft机制快速选出领导者,Broker们则完成自我注册和心跳维持,确保集群各组件的协作顺畅。
在调试层面,适当提升Kafka服务器的日志输出详细度,可以清晰捕获包括Broker注册、心跳、元数据拉取及控制器间领导选举等关键请求,从而深入洞察各环节的真实数据流和交互逻辑。通过对这些请求日志的分析可以发现控制器间元数据同步严格遵循拉取式模式,领导者不会主动推送更新,而是等待跟随者踢馆式拉取,保证同步过程的透明且有序。同时,Broker向单一领导控制器发起请求确保操作时效和便捷,减轻了网络负担。Kafka KRaft的出现不仅标志着Kafka迈入了新的技术世代,也让元数据管理更加高效、易扩展。相比ZooKeeper依赖方案,KRaft极大降低了运维门槛,简化了系统组件。控制器节点的Raft一致性保证了元数据的状态准确无误,避免了ZooKeeper中潜在的分区脑裂问题,提升集群的整体鲁棒性。
此外,随着Kafka生态系统的不断完善,KRaft支持的功能也日益丰富,未来可望在Kafka流式处理和跨集群复制中发挥更大作用。理解KRaft架构的通信流程,对于Kafka用户合理部署高可用集群、快速定位故障以及优化性能均有重要帮助。随着社区对KRaft的持续投入,相信这一架构将成为Kafka元数据协调的主流解决方案。Kafka KRaft以其独特的Pull驱动同步和单一领导控制器设计,开创了分布式消息系统控制平面的全新篇章,让Kafka集群的稳定性、扩展性和可维护性均迈上新的台阶。未来任何希望构建下一代实时数据平台的架构师与开发人员,都应密切关注并深刻掌握Kafka KRaft的内在工作机制。