随着大数据技术的发展,流处理作为实时数据分析与计算的重要手段,受到越来越多企业与开发者的关注。Apache Flink作为流处理领域的领先框架,提供了灵活强大的时间语义支持,而水印(Watermark)机制更是其核心组件之一,直接关系到事件时间的准确处理与窗口计算的正确触发。在Flink SQL中,理解和合理使用水印机制,可以有效解决数据乱序、延迟和窗口关闭时机难题,提升流应用的准确率和稳定性。 时间是流处理中的灵魂,无论是批处理还是流处理环境,都不可或缺。时间的维度决定了事件的顺序、计算的正确性以及结果的时效。特别是在实时数据中,事件时间(Event Time)和处理时间(Processing Time)两个概念尤为重要。
事件时间指的是数据发生的实际时间,而处理时间则是指数据被处理的时间,二者可能因为网络延迟、系统异常等因素而产生较大偏差,影响统计与分析结果的准确性。 Flink SQL对时间的支持建立在时间属性的基础上,主要分为事件时间属性和处理时间属性。事件时间基于数据本身携带的时间戳,例如Kafka中消息的创建时间。处理时间则是流处理作业所处的系统时间,即实时的墙钟时间。水印机制专注于事件时间的管理,通过水印来告知系统某一时间点之前的数据已全部到达,允许系统关闭相应时间窗口并输出计算结果。 水印的出现源自流数据的天然延迟与乱序问题。
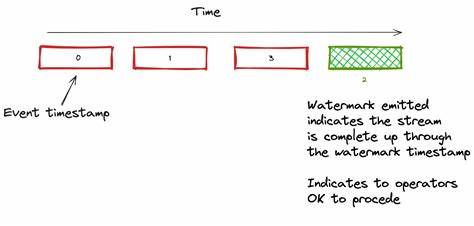
在真实应用场景中,网络波动、数据分区不同步或生产者延时推送等因素,常导致事件按照事件时间顺序到达系统的情况变得复杂。简单依据事件时间完成窗口计算,将面临部分迟到数据被忽略,甚至统计偏差的风险。水印机制本质上是对这种不确定性的补偿和管理策略,它通过在事件时间上设置一个“进度线”,表示当前系统认为全部在此时间点之前的事件已经处理完成。 在Flink SQL的表定义中,引入水印通常通过WATERMARK FOR 语句来实现。它让Flink能够自动解析流中数据的事件时间列,并定义水印的生成规则,通常体现为事件时间减去一个延迟阈值,这个延迟值代表允许数据乱序的最大时间范围。比如定义“WATERMARK FOR created_at AS created_at - INTERVAL '5' SECOND”,意味着系统允许事件乱序延迟5秒钟,超出此范围的数据会被判定为迟到数据,默认情况下会被丢弃。
然而水印生成并非无懈可击,尤其在分布式数据源环境,如Kafka多个分区的场景下,水印更新依赖所有分区中最小的水印时间。如果某个分区长时间无数据(称为闲置分区),它的水印将落后,阻止整体水印前进,导致窗口无法及时关闭,影响处理结果的输出。为此,Flink引入scan.watermark.idle-timeout参数,通过设置超时时间让系统忽略长时间无数据的分区,推动水印继续前进,保障应用的持续流畅运行。 Kafka作为分布式消息系统,与Flink高度集成,为实时流计算提供数据源。Kafka消息自身包含时间戳信息,既可作为事件时间(如消息内部字段created_at),亦可作为处理时间的参考(Kafka记录产生的时间戳)。Flink通过元数据列方式访问Kafka消息的时间戳,使开发者能根据不同业务需求灵活设定事件时间字段及水印策略。
Flink SQL数据表中,事件时间的时间属性必须显式声明水印策略。缺少有效水印定义,会导致时间窗口无法触发计算,SQL查询报错“window function requires the timecol is a time attribute type, but is TIMESTAMP(3)”即为典型错误提示。正确配置水印使得TUMBLE、HOP等基于时间的窗口函数得以正常运行,输出准确而完整的结果。 流水线中的水印生成策略影响整个流处理系统的表现。默认情况下,Flink以固定间隔(例如200毫秒)周期性发送水印。也可以调整为事件驱动模式,实现每接收一条事件即生成水印,以获得更高的处理确定性。
然而事件驱动水印会带来性能压力,需要根据实际应用场景权衡吞吐量和延迟需求。 面对迟到数据,Flink SQL默认丢弃超过水印范围的数据记录,避免错误影响系统状态。但业务侧可通过调整水印延迟设置,或配置允许迟到数据的处理逻辑(需借助Flink DataStream API扩展),平衡数据完整性与延迟容忍度。了解这种迟到数据和乱序数据的区别,对于设计合理的流计算方案至关重要。 在Flink SQL使用水印时,表结构定义的调整和及时监控水印进度不可忽视。通过加入Kafka分区元数据,观察各分区数据流和水印变化状态,可以快速定位数据倾斜或闲置造成的水印滞后问题。
结合Flink Web UI中的水印监视功能和REST API接口,开发者能够动态追踪水印进度,洞察流处理作业的实时性能和数据处理进展。 实践中,调整scan.watermark.idle-timeout参数解决闲置分区阻碍水印前进的难题。重新设计Kafka消息发送策略,保证所有分区都有数据流入,也有助于水印加速推进。正确的事件时间字段设计,结合精准的水印定义,形成科学的数据时间语义体系,是Flink流处理作业稳定高效运行的前提。 水印作为事件时间处理的技术核心,体现了流计算系统如何在无界、乱序的现实世界数据中,平衡时效与完整性的复杂课题。从事件时间属性申明、水印生成策略,到闲置分区处理,再到业务窗口聚合应用,系统理解和合理配置水印机制,确保数据分析结果的正确与及时,是Flink SQL流处理设计师必备的技能。
展望未来,随着实时计算需求的激增,水印机制及其优化策略将持续演进。动态自适应水印生成、对迟到数据更智能的容忍与修正、多来源复杂事件时间管理等方向为社区关注重点。基于Flink SQL的水印机制,不仅助力实时业务体系构建,也为大数据生态中的时间语义处理提供强大支持。 深入学习水印相关知识,建议结合Flink官方文档、社区优质视频和会议分享,反复实践调整测试。理解事件时间与处理时间的差异,明白水印如何驱动流处理作业的运行节点前进,是系统设计和调优的重要基础。水印挑战虽多,但一旦掌握,必将开启更精准、更高效的实时数据分析新篇章。
。