近年来,随着大型语言模型(LLMs)的广泛应用,模型的计算资源消耗和存储需求日益成为制约其普及的关键瓶颈。量化技术作为一种有效的模型压缩手段,备受研究者和工程师关注。Unsloth团队最新推出的Dynamic 2.0 GGUFs量化方法正是在此背景下应运而生,成为推动高效推理与微调的划时代技术。Dynamic 2.0不仅极大地优化了量化策略,同时在准确率和效率之间实现了更优平衡,引领了量化模型的新趋势。Dynamic 2.0的核心优势在于其全新设计的层选择与量化方案。传统量化往往只调整模型中的部分层,而Dynamic 2.0则采用动态机制,针对每个层的特性采用不同的量化类型。
这种针对性调整使得整体模型在减小存储空间的同时,最大限度地保持了模型的表现力和准确性。该方法集成了多种量化格式,如Q4_NL、Q5.1、Q5.0、Q4.1和Q4.0,特别针对Apple Silicon及ARM架构设备实现了优化,极大地拓宽了模型适用范围和设备兼容性。Unsloth Dynamic 2.0同样注重量化过程中的校准数据集设计。采用超过一百五十万令牌的高质量、人工筛选清洗数据集进行模型校准,有效避免了传统基于维基百科数据的校准过拟合问题。尤其对于指令型(Instruct)模型,使用专门优化的多样化校准数据,显著提升了对话性能和泛化能力。技术社区中广泛使用的KL散度指标也被Unsloth团队重新定义为量化评估的金标准。
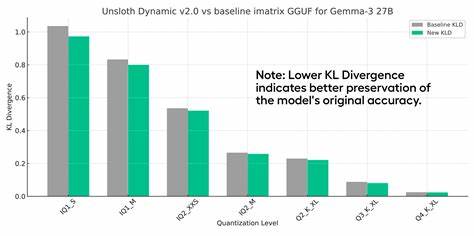
其依据《Accuracy is Not All You Need》等前沿研究,强调KL散度比困惑度指标更能精准度量量化误差的分布差异,避免数值抵消导致的误判。同时KL散度与答案正确性“翻转”现象高度相关,有助于真实反映在不同层或权重裁剪过程中的性能变化。在模型性能表现方面,Unsloth Dynamic 2.0展现了卓越的实力和竞争力。以DeepSeek V3.1模型为例,采用其3-bit Dynamic量化的GGUF格式在Aider Polyglot测试中取得了75.6%的成绩,甚至超越一些全精度的先进模型。该量化方法适用于多种模型架构,包括MoE(专家模型)和非MoE,使得其应用范围更广泛。值得一提的是,Unsloth团队积极与多家知名AI厂商和开源项目合作,针对Qwen3、Meta的Llama 4、Mistral的Devstral、Google的Gemma系列及微软Phi系列等模型进行了深入的Bug修复和优化。
这些合作不仅提升了量化模型的稳定性,也使得推理准确率显著提升,为量化模型的开源生态注入新动力。在复杂的MMLU(多领域语言理解测试)上,Dynamic 2.0的精度表现尤为突出。研究人员专门设计并实现了全流程重现的MMLU评测代码,解决了许多先前被忽视的细节问题,比如Llama 3令牌的特殊分割。最终,Dynamic 2.0量化模型的MMLU准确率接近甚至超过了全精度版本,体现了其科学严谨的设计理念。Gemma 3量化感知训练(QAT)成果同样令人瞩目。Unsloth Dynamic 2.0对标Google官方QAT版本显示,12亿参数量级的Q4_0 GGUF版本在5-shot MMLU测试中达到了超过67%的准确率,几乎与原始bfloat16模型无异,极大地提升了存储和计算效率。
团队还推导出专门衡量量化模型综合性能的效率指标,将准确率和磁盘空间统一考量,为量化方案的选择与优化提供指导。除了性能提升,Dynamic 2.0也关注实用性与易用性的结合。用户可以在主流推理引擎如llama.cpp、Ollama和Open WebUI等平台上轻松加载并执行Dynamic 2.0 GGUF模型,享受更高的推理速度和更低的资源消耗。详细的安装、更新及操作文档为初学者和开发者提供充足支持,让复杂的微调和推理过程变得更加简单友好。对于Llama 4 Scout版本,Unsloth Dynamic 2.0还提供了针对模型特有的RoPE缩放和QK Norm配置的定制修复,有效解决了社区中普遍存在的兼容性和准确率问题。从底层实践到社区协作,Unsloth Dynamic 2.0体现了开放协作与技术创新的双重优势。
未来,随着更多模型不断升级,Dynamic 2.0作为标准量化方案的地位将持续巩固。团队的后续计划也包括将Dynamic 2.0技术推广至更多4-bit安全张量量化版本,为广大AI从业者带来更多性能卓越且稳定的模型选择。综上所述,Unsloth Dynamic 2.0 GGUFs不仅代表了目前量化技术的前沿水平,更为大型语言模型的高效部署和微调提供了强大动力。其在提升推理准确性、减少计算资源和存储占用方面的优势,使其成为AI技术生态中不可忽视的重要力量。随着应用场景的不断丰富与硬件加速的普及,Dynamic 2.0有望成为引领智能模型量化未来发展的基石,推动人工智能迈向更高效、更智能的新时代。