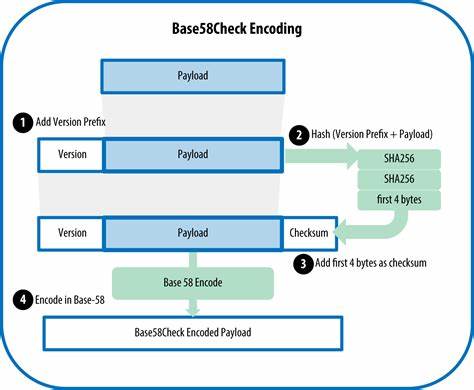
随着数字信息的广泛传播和存储,如何高效且安全地编码二进制数据成为了信息技术中的核心问题。Base58和Base85作为两种在业界广泛使用的编码方案,都致力于将复杂的二进制信息转换为人类更容易识别和处理的字符形式。虽然它们同属于编码领域,但各自拥有不同的设计理念、字符集和应用场景。深入了解这两者的差异与特点,对于开发者、数据科学家乃至密码学领域的专业人士来说,具有重要的指导意义。Base58编码最初因比特币系统的出现而被广泛关注。它通过排除易混淆的字符,利用58个特定字符表示数据,极大地减少了因视觉混淆造成的输入错误。
在编码时,Base58严格执行数学上的58进制转换,目标是确保编码后数据紧凑且易于人工处理。通过避免类似字母“O”和数字“0”,或字母“l”和数字“1”的混淆,Base58在数字货币地址、安全密钥等领域发挥了关键作用。既保障了数据的可读性,也提升了在实际操作中的容错能力。相较之下,Base85编码则追求更高的编码效率。它使用85个可打印ASCII字符进行编码,将4字节的二进制数据转化为5个字符。相比于传统的Base64需要6个字符来表示相同的数据,Base85能够明显提升数据的紧凑度。
Base85的设计灵感可追溯到早期计算机中类似二进制编码十进制(BCD)的想法,将二进制分块处理,利用丰富的字符集极大缩减了编码长度。在PDF文件格式以及版本控制系统Git的补丁编码中,Base85被广泛应用。它由于编码每个32位字独立处理,因此在计算效率和实现复杂度上表现良好。但Base85的字符集囊括了诸多视觉上相似的符号,如大写字母“O”、数字“0”以及小写字母“o”,这使得纯粹依靠视觉辨别时容易发生误读。这种权衡使Base85更适合机器处理的场景,而非人工录入的环境。对比两者的字母表,Base58拥有一个经过精心挑选且去掉容易混淆字符的字母表,如包含数字“1”但不含小写字母“l”,包含小写字母“o”但不含大写字母“O”或数字“0”。
Base85则包括所有可打印字符,从符号到数字再到大小写字母,虽然字符丰富提升编码效率,但降低了输入的容错率。编码示例中,以十六进制数0xCAFEBABE为例,Base58编码过程直接将其视为一个大整数,进行58进制转换,最终使用指定的字母表拼接形成6Bx4TP的编码。而Base85的编码则是将数值分成单独4字节的块,分别转换成对应的Base85字符。如果错误地将整体数值视为一个大整数进行Base85转换,则会得到不正确的数据串,体现出Base85编码时对数据分块处理的重要性。扩展到八字节数据,Base58的编码依旧将整体数据转换为58进制,而Base85仍然采用每4字节分别编码的策略,产生两段编码拼接的结果。这样的设计差异表明,Base58更适合处理整体数字进行编码的场景,而Base85则更适合固定长度分块编码,尤其适用于文件格式和通信协议设计。
应用层面,Base58因其简洁且容错性强,常见于密码货币地址生成、密钥编码,以及需要人工输入场景的编码操作。Base85则因高效率、紧凑的编码输出,被大量用于计算机内部数据交换、压缩传输以及特定文件格式的编码,如PDF等。开发者在实际选择时需权衡效率与易用性。Base58虽然编码长度较长,但提高了数据的可读性和输入准确性,适合面向用户界面和安全要求高的场景。Base85则偏重于减小传输数据包体积和提升编码速度,适合机器自动处理或对传输效率要求高的系统。除此之外,还需注意业界Base85编码存在不同变体,不同软件可能采用不同字符集,这给跨平台兼容性带来一定挑战。
相反,Base58由于标准定义明确,且使用稳定的字母表,兼容性更好。综上所述,Base58与Base85各有优势与不足。Base58凭借其字符选取策略及数学基础,成为数字货币领域不可替代的工具,而Base85凭借编码高效的特性,在文档格式和版本控制中扮演着重要角色。理解二者的核心原理及应用限制,有助于开发者在设计系统时做出合理决策,提升整体数据处理的性能与安全性。未来随着数字化进程的加深,二进制数据编码的需求不断多元化,Base58和Base85仍将是不可忽视的重要技术方案。掌握其原理及应用,将有助于在大数据、区块链、云计算等领域更好地应对编码挑战,推动信息技术发展新高度。
。