近年来,大型语言模型(LLMs)在自然语言处理领域取得了显著进步,尤其是在化学科学的应用方面表现尤为引人注目。随着技术的发展,人工智能不仅能够理解人类语言,还开始承担起化学知识的传递与复杂推理的任务,甚至出现可以在化学问题上挑战甚至超越部分人类专家的现象。然而,人们对这些模型真正的能力范围和潜在不足仍缺乏深入、系统的认知。为了填补这一空白,科学界开展了系统性研究来评估大型语言模型在化学知识和推理方面的表现,并将其与人类化学家的专业能力进行对比。基于大量精心设计的问题集和评测框架,这些研究不仅揭示了现阶段模型的优势和短板,也为未来提升这类技术提供了宝贵参考。 大型语言模型的崛起带来了化学研究的新机遇。
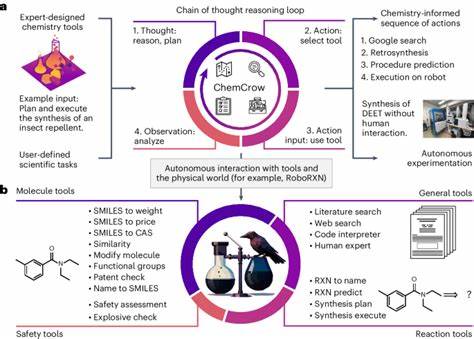
它们通过在海量文本数据上进行训练,积累了丰富的化学相关知识,能够自动生成化学反应方案、预测分子性质甚至辅助实验设计。特别是通过结合外部工具,如文献检索系统和化学反应规划器,模型的推理能力得到进一步增强,展现出类人甚至超人的创新潜力。这种以文本为中心的学习方式使得模型不仅能执行已知任务,还能处理许多传统数据库无法覆盖的复杂推理和组合问题。这一点在化学领域尤为重要,因为许多化学知识和洞察本质上是以书面形式存在的——包括论文、专利和教材等。通过挖掘广泛的文本资料,LLMs有望释放这些隐含知识,促进科学发现的加速。 为了全面衡量大型语言模型的化学能力,科研团队开发了名为ChemBench的自动化评测框架。
该框架囊括了超过2700对问题和答案,覆盖了从基础化学到更专业领域的多样化知识和技能。问题设计既包括选择题,也包括开放式问答,考查模型的知识掌握、推理能力、计算技能和化学直觉等多维度能力。此外,ChemBench对问题进行了难度分级和技能分类,使得评估结果更具细致性和指导意义。更重要的是,研究还邀请了多位经验丰富的化学专家参与评测,建立了人类专业水平的基准。这种结合机器和人类的对比评测,为理解模型在化学领域的实际表现提供了坚实依据。 令人瞩目的是,ChemBench的测试结果显示,部分最先进的语言模型在总体表现上已经超越了参与研究的人类化学专家。
在回答多样化的化学问题时,这些模型不仅具备强大的知识储备,还展现出一定程度的复杂推理能力,尤其在基础化学和技术性化学领域表现优异。某些开源模型甚至能够与最顶尖的专有模型相媲美,表明开源社区在推动化学人工智能应用方面的巨大潜力。然而,这些模型仍面临不少挑战。比如,它们在涉及知识密集型的问题(如分子安全性评价和分析化学)中表现相对较弱,显示出对某些事实知识的记忆不足。此外,对于涉及分子结构推断的题目,模型往往不能像人类化学家那样进行深度结构分析,推测分子的对称性或核磁共振信号数目等问题时,准确率明显下降。 此外,值得关注的是大型语言模型在自我评估和置信度判定方面普遍存在不足。
实验发现,模型们在回答错误时可能表现出过度自信,甚至比正确回答时的置信度更高。这种误判不仅可能误导用户,特别是缺乏专业背景的非专家,带来潜在风险,也对在化学安全或实验设计等关键领域的实际应用造成隐患。因此,提升模型的置信度校准能力,或者将其与专家监督和多模态验证结合,成为亟待解决的核心问题。 化学领域的知识和推理极具复杂性。除了事实记忆外,化学问题常常需要层叠的逻辑推导、多角度思维和实验室经验的融合。当前大型语言模型虽然在文字层面展现了极强的理解能力,但对于化学结构的空间信息处理仍比较有限。
比如,模型倾向于依据训练语料中分子的出现频率和关联性作答,而非真正“理解”分子的三维构型及其化学性质之间的内在联系。这导致模型在推断复杂化合物、构象异构体和谱图解析时表现不佳。未来,将分子图形学、量子化学计算与语言模型结合,或通过训练多模态模型,将是改进推理深度和精度的重要方向。 化学家与大型语言模型的关系也被重新定义。随着模型能力的提升,化学专业教育和科研工作模式正发生变革。传统依靠背诵和机械计算的教学方法,在智能辅助系统面前显得不够高效。
反之,更强调批判性思维、整合分析和创新精神的培养变得愈加重要。模型可以辅助学生解答典型题目,为研究人员提供快速的信息获取和初步假设验证,从而释放更多精力用于高阶创新。与此同时,化学专家需要具备鉴别模型输出可靠性的能力,有效利用人工智能工具,同时防范其局限带来的风险。 在安全和伦理层面,化学领域应用大型语言模型也带来挑战。化学知识的双重用途风险亟须关注:同样的技术既可用于设计新药,也可能被滥用于制造有害物质。模型生成错误或误导性信息,尤其是涉及化学品安全和毒性的信息时,可能导致严重后果。
因而,建立严谨的监管框架、设计安全防护机制并强化用户教育成为关键课题。此外,专门针对化学语义和安全领域的训练数据筛选与增强,对于限制模型误用和提升整体安全性至关重要。 未来,ChemBench等评测平台将推动大型语言模型在化学领域的持续进步。通过标准化、多维度的性能衡量,不仅有助于开发更强大、更可靠和更具解释性的模型,也为学术界与工业界搭建了透明的对话桥梁。模型研发者能够基于丰富的反馈不断优化算法和训练策略;化学社区则能够借助评测结果更合理地选择和应用人工智能工具;政策制定者亦能据此制定科学合理的监管政策。 在科学研究层面,融合文本数据与实验数据、图像和结构信息,将赋予模型更强的多模态理解能力。
人工智能助力的自动化实验平台,已经开始展现将自然语言指令转化为精确实验方案的潜力,推动化学研究进入数据驱动与智能协同的新纪元。与此同时,AI的化学偏好判断能力仍处于初步阶段,目前模型在模拟人类化学直觉的任务中表现不佳,但这为未来个性化化学探索与自动化优化开辟了广阔天地。 综上所述,大型语言模型在化学知识掌握和推理能力方面展现出令人赞叹的潜力,甚至在某些领域超越了人类专家的表现。但模型的不足和风险也不可忽视。未来的发展将需要跨学科协作,结合化学专业知识、机器学习技术及伦理安全意识,推动模型不断完善。与此同时,化学教育和实践也将随之转型,形成“人机协作”的新格局,使科学探索更高效、更创新,同时更安全可靠。
借助系统化的评测框架和开源工具,化学界正站在实现智能化研究的风口浪尖,迎接一个以语言为媒介,拥抱智能的崭新时代。