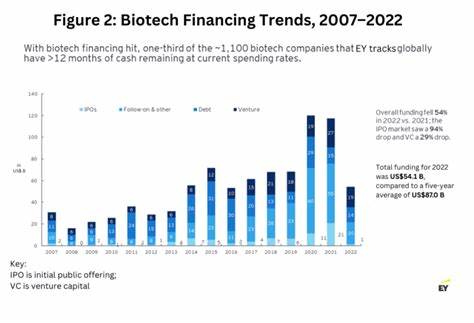
在大数据处理领域,Apache Spark作为一个强大的分布式计算引擎,广泛应用于海量数据的读取和写入。在许多数据仓库或数据湖场景中,数据通常会以分区文件的形式存储,尤其是时间维度分区,如按年、月、日、小时等层级嵌套的分区。深度分区结构不仅有助于数据的管理和查询优化,但也给数据管道的设计和实现带来了不小的挑战。如何利用Spark高效地读取并写入这样复杂、深层的分区文件,成为数据工程师必须攻克的课题。本文将详细介绍如何通过Spark实现深度分区文件的处理,涵盖读取策略、分区列提取、写出方法及性能优化技巧,希望为您的项目实践提供实用参考。 深度分区文件的典型应用场景主要出现在日志数据、电商交易数据和IoT时序数据处理中。
比如,在数据存储结构上形成year=2023/month=08/day=15/hour=13的多层目录,每个目录下存放着对应时间范围内的数据文件。这样的分区设计,可以大幅提升查询效率,但也意味着在读写时必须准确识别和处理这些多级分区目录,保持分区信息的完整性,否则会导致数据错乱、查询不准确甚至资源浪费。 传统Spark读取方式对于已知分区结构通常采用手动指定路径或者通过路径模式匹配来加载数据,但对于动态且分区深度较大的场景,这种方式往往效率低下且容易出错。例如,如果你想要读取所有year、month、day和hour层级的目录下的文件,必须提前知道所有分区的具体组合,或者进行复杂的递归扫描,既繁琐又不可靠。Spark自带的recursiveFileLookup参数虽然支持递归读取,但读取时并不能自动生成对应的分区列,这就需要额外方法从文件路径中提取分区信息。 在实际操作中,解决深度分区读取问题的关键技术点在于借助input_file_name()函数获取文件的完整路径,并利用正则表达式(regexp_extract)从中提取出层级分区对应的字段值。
通过这一方法,可以自动识别每条数据对应的year、month、day、hour等信息,动态构建分区列。然后在写出时,利用Spark的partitionBy功能将数据按相应分区列组织成目录结构,确保目标路径下文件符合预期的分区层次。 具体来说,首先构建SparkSession环境,确保设置了递归文件搜索和文件过滤选项,以便高效读取包含多级文件夹的源数据。随后,读取数据时不必事先知道具体分区值,而是通过input_file_name函数获取当前处理文件的路径信息。利用Spark SQL的regexp_extract方法,结合合适的正则表达式分别匹配路径中的year、month、day、hour等字段,将这些抽取的字段以新列添加到DataFrame中。这一步为后续的分区写入打下基础。
数据写出阶段,核心是调用DataFrame的write接口,设置格式(例如csv或parquet)、写模式(如overwrite),并使用partitionBy指定上述抽取的分区列作为目录层级。Spark会根据这些列自动创建对应的分区文件夹结构,从而实现数据逻辑分区和物理分区的一致,方便后续查询和操作。 这一方案具备极佳的通用性,无需事先硬编码分区名称或路径,适应性强,简化深度分区文件的迁移、备份及转换工作。同时,基于正则表达式提取结构,保证分区的准确性和一致性。在大规模数据处理场景下,避免了对分区的静态枚举带来的低效和易错问题,提升了整个数据流水线的健壮性和自动化水平。 当然,在应用过程中,也要注意性能调优。
例如,合理设置Spark的分区数,避免shuffle时数据倾斜,选用parquet格式以获得更佳的存储压缩和读取性能,另外针对特定业务可在正则表达式或路径解析上做更精细的定制。 此外,切忌完全依赖路径结构进行分区推断,应确保分区字段在数据中同步存在,或者通过验证避免误解析。保持代码的可维护性和可扩展性,也是长远项目成功的必要保障。 总结来说,使用Apache Spark处理深度嵌套的时间分区文件,结合input_file_name与regexp_extract动态提取分区字段,再通过partitionBy写出数据,是一种简洁高效且具备通用性的解决方案。该方式不仅适合数据迁移和备份情境,也广泛适于日常ETL任务和数据仓库建设,极大提高了开发效率和处理灵活度。希望更多数据从业者能掌握并应用此方法,为大数据项目带来稳定可靠的分区文件管理体验。
随着数据规模不断扩展和分区策略愈加复杂,深入理解和灵活运用Spark的分区读取与写入机制必将成为提升数据工程实力的核心技能之一。未来,结合Spark生态的丰富功能,如Delta Lake、Iceberg等数据格式与元数据管理工具,可以进一步增强深度分区数据操作的便捷性和智能化水平。持续关注这些技术发展,结合自身业务场景灵活实践,将助力企业构建面向未来的高效数据平台。 。