在数据工程与机器学习的日常工作中,数据往往被存放在数据库中,而模型推理通常在数据库之外进行,这带来了数据搬移、重复存储和开发运维复杂度等问题。Infera是一个以Rust编写的DuckDB扩展,旨在将机器学习推理能力原生地带入数据库查询流程,从而让开发者可以直接在SQL语句中调用模型,极大简化数据到预测的路径。Infera使用Tract作为推理引擎,支持ONNX模型格式,并提供远程与本地加载、模型自动加载、列向量与张量输入等功能,这使得它成为面向分析场景的轻量级推理方案之一。核心设计与实现细节Infera以DuckDB扩展的形式工作,这意味着用户可以在DuckDB会话内通过SQL函数来加载、调用和卸载模型。核心推理引擎使用Tract,Tract是一个Rust生态中的轻量级ONNX推理库,专注于在CPU上高效运行并支持常见的神经网络操作。Infera将模型以名称注册在扩展的模型管理器中,支持从本地路径或远程URL加载ONNX文件。
加载后的模型在内存中驻留,并可以被多个查询线程安全访问,从而实现高并发推理。模型调用接口设计简洁直观。典型的操作流程包括:使用SQL函数 infera_load_model(name, url_or_path) 加载模型,使用 infera_predict(name, col1, col2, ...) 或 infera_predict_tensor(name, tensor_blob) 在查询中对表列或原始张量数据进行推理,最后通过 infera_unload_model(name) 卸载模型释放资源。扩展还提供 infera_get_version() 等管理函数,方便运维和调试。功能亮点与适用场景Infera能够把模型推理当作SQL查询的一等公民,这为若干场景带来明显价值。实时或近实时的分析场景能够直接在数据层进行评分与打分,避免了数据导出到外部服务或批处理系统的额外开销。
数据仓库与报表系统可在生成报表时嵌入模型预测结果,简化报表管线。小型在线服务或轻量推理管道可以在单机DuckDB实例中完成数据存储与模型推理一体化部署,减少运维复杂度。Infera支持本地和远程模型加载,便于团队采用集中化模型仓库或直接拉取公开模型库的资源。支持对表列进行逐行推理与对原始张量做批量预测,允许用户按需选择行级服务或批量处理,从而兼顾延迟与吞吐。部署与快速上手在DuckDB中使用Infera有两条主要路径。第一种是从DuckDB社区扩展仓库安装并加载扩展,适用于快速试验与生产环境中支持的预编译版本。
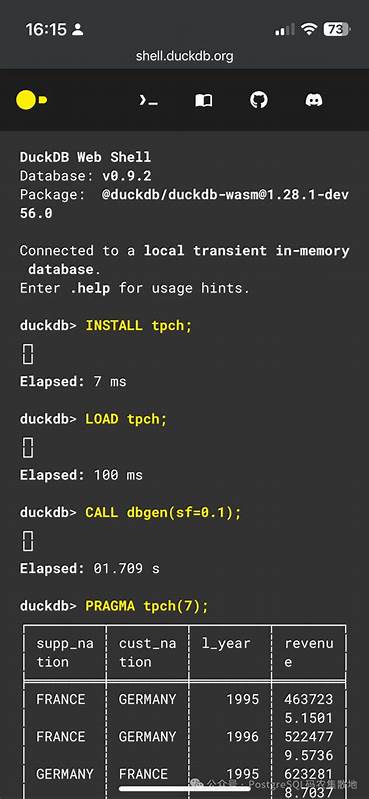
常用的SQL命令为:install infera from community;load infera;第二种是从源码构建,适合需要定制或在特定DuckDB版本上静态链接的场景。典型流程包括克隆仓库、递归拉取子模块、执行 make release 以编译扩展,然后在本地DuckDB二进制中通过 load 'path/to/infera.duckdb_extension'; 加载扩展。要注意构建出的扩展仅与其编译时所使用的DuckDB版本兼容。加载模型与推理示例可以非常简洁。以一个简单的线性模型为例,加载并预测的SQL如下:select infera_load_model('linear_model', 'https://github.com/CogitatorTech/infera/raw/refs/heads/main/test/models/linear.onnx');select infera_predict('linear_model', 1.0, 2.0, 3.0);select infera_unload_model('linear_model');性能与资源管理考量Infera基于Tract的运行时,优化点主要在模型结构、输入管道与批处理策略上。Tract擅长在CPU上执行许多常见操作,对于没有复杂自定义算子的ONNX模型,运行效率较高。
为了获得最佳性能,应当尽量选择适合CPU推理的模型架构,避免对GPU特性或专有算子有强依赖的模型。如果需要更高性能或GPU加速,可能需要使用诸如ONNX Runtime或TensorRT等工具,并通过外部服务方式来实现更复杂的部署。为了减小内存占用并提升吞吐,建议采用批量推理的方式。将多行数据打包为一个张量传入 infera_predict_tensor 可以减少模型初始化与调用开销。对于列到张量的转换,最好在SQL层面提前完成必要的类型转换与缺失值填充,保证模型输入张量的数据类型一致。Infera支持多输出模型,但调用时需明确模型输出的结构,后续SQL处理也应对应解析不同的输出维度。
模型兼容性与调试Infera依赖ONNX格式与Tract的算子支持,因此不是所有在ONNX生态中导出的模型都能直接运行。常见问题包括不受支持的自定义算子、较新opset版本的不兼容以及模型中包含稀有或未实现的图操作。调试时可以先在Tract本地运行模型,确认输入数据形状和类型后再在DuckDB中调用。将模型导出为较低opset版本并避免使用自定义或实验性算子通常能提高兼容性。模型量化与简化工具可以在不显著牺牲精度的前提下,减小模型体积并提高CPU推理效率。与外部推理服务的比较将推理嵌入数据库与使用外部推理服务各有优劣。
内置扩展如Infera的优势在于简单、低运维、数据在库内无需导出且延迟较低,特别适合小到中等规模的批量推理与分析场景。外部推理服务的优势在于能够调用更强大的推理后端、支持GPU加速、能够横向扩展以应对高并发在线请求。产品实践中可以根据需求混合使用:分析型查询与离线评分在DuckDB + Infera中运行;对高并发低延迟的在线推理仍然使用专用的推理服务。实践建议与最佳做法在使用Infera时,先从小规模原型入手,验证模型在Tract上的兼容性和对业务数据的预测质量。尽量在模型导出阶段关注ONNX opset版本和算子使用,必要时进行模型裁剪或替换不兼容的算子。对于批量推理任务,合并多行输入为张量形式有助于提高吞吐。
在SQL层面做好数据清洗和类型规范,避免在扩展内部做复杂的数据预处理,从而让推理逻辑更专注于模型调用。资源监控和模型卸载也非常重要。长期驻留的大模型会占用大量内存,合理设置模型生命周期与卸载策略,或者通过Infera的自动加载目录功能只加载必需模型,可以降低内存压力。对于多模型场景,评估并行加载和并发推理对CPU资源的影响,避免因过度并发导致的上下文切换和缓存抖动。生态整合与模型来源Infera推荐使用ONNX Model Zoo等公开资源快速试验模型。Hugging Face等平台也提供大量预训练ONNX模型,适合做功能验证或基线测试。
对于企业级部署,建议建立内部模型仓库并配套版本管理策略,结合标签用于在DuckDB中按需加载特定版本的模型。模型的权限管理、审计日志与可解释性分析仍需在上层系统设计中考虑,因为在数据库内部运行推理并不自动提供模型治理能力。适用场景示例定期批量特征工程和评分可以完全在DuckDB中完成,分析师可以写一个SQL查询在聚合后直接调用模型,输出带有预测列的结果表并持久化。实时报告场景可以在报表生成时动态计算预测值,从而在展示中提供最新的预测信息。小型数据产品可以将DuckDB作为数据与推理的单体部署,减少系统间通信并降低运维门槛。学术和研发团队可以利用Infera作为实验平台,快速验证不同模型在真实数据库数据上的效果。
局限与未来发展方向当前Infera处于早期开发阶段,因此在稳定性、算子覆盖和性能方面还有提升空间。Tract本身侧重于CPU执行,若对GPU加速有强需求,需要借助其他推理后端或外部服务。复杂模型和含有自定义算子的网络可能无法直接运行,需要开发者在模型导出或转换阶段做额外处理。未来可以期待更丰富的模型管理、运行时优化、更多后端支持以及更完善的监控与治理功能。贡献与许可Infera采用双重许可(MIT与Apache-2.0),便于在开源和商业项目中使用并进行二次开发。社区贡献对于扩展算子支持、增强文档和完善示例非常重要。
对于希望参与的人士,阅读仓库中的CONTRIBUTING.md和ROADMAP.md可以快速上手,提交问题和合并请求能够帮助项目更快迭代。总结与建议将机器学习推理嵌入数据库查询流程是一个能显著简化数据科学和工程流程的思路。Infera通过在DuckDB中提供原生推理能力,使数据从存储到预测的路径变得短而直接。对于以分析为主、在CPU环境中运行模型的场景,Infera是一个值得尝试的轻量级方案。在采用过程中,应重视模型兼容性、批处理策略和资源管理,并针对用例选择合适的部署方式。结合内部模型仓库与标准化导出流程,可以把Infera变成团队快速试验与生产化评分的重要工具。
尝试从一个简单的线性模型入手,逐步扩大到更复杂的网络,会是探索在数据库内部实现推理的稳妥路径。 。