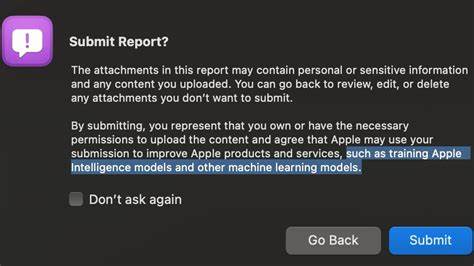
近年来,人工智能技术在各行各业的发展日益迅猛,苹果作为全球领先的科技企业,不断将AI元素整合进其产品和服务中,以提升用户体验和系统智能化水平。然而,最近苹果在其错误报告反馈机制中新增的一条隐私声明引发了用户和开发者广泛的担忧和讨论。新的条款中指出,用户上传的错误报告内容,包括包含敏感信息的系统诊断日志,可能会被用于训练苹果的人工智能模型。这一做法在社交平台上引起了激烈的反响,反映出用户对隐私保护和数据使用透明度的新期待。苹果的错误报告系统长期以来是用户与公司之间沟通产品问题、反馈体验的重要渠道。通常用户在遭遇软件bug时,会通过反馈助手提交详细日志和诊断数据,协助苹果定位和修复漏洞。
过去,用户往往基于对苹果隐私政策的信赖,认为提交的诊断数据主要被用于改进产品功能,而不会被用于其他商业或研究目的。然而,新增的隐私提示中明确提及,提交的内容“可能被用于训练苹果智能模型和其他机器学习模型”,这一表述令不少用户感到措手不及。他们在不了解完整背景的情况下,面临着个人敏感信息被用于AI训练的可能性,且缺乏明确的选择或拒绝权,这在业内引发了关于用户同意边界和数据使用伦理的大讨论。许多技术从业者和开发者表达了对苹果此举的失望。他们认为,错误报告本质上是帮助公司改进产品的工具,将其中包含的私人数据用于AI模型训练,是对用户信任的背弃。这不仅削弱了部分用户愿意主动提交错误反馈的积极性,也可能导致苹果在开发者社区的声誉受损。
此外,对于系统诊断数据中常含有的诸如网络连接信息、运行日志、硬件状态甚至用户操作习惯等敏感内容,一旦被用于大规模机器学习训练,如何保证数据的去标识化和安全性,成为公众和隐私专家关注的重点。有关苹果的解释显示,此举旨在借助先进的机器学习技术,更精准地识别和理解软件问题,推动自动化调试和智能化维护的发展。理论上,这符合苹果长期以来宣传的用户体验至上和技术创新的宗旨。然而,许多声音指出,苹果未能妥善就此告知用户,也缺乏明确的主动选择机制,使得其隐私政策显得含糊且默认授权成为常态。在技术伦理层面,利用用户错误报告数据训练AI模型涉及多个风险面向。首先是隐私泄露风险,系统诊断日志时常包含手机号码、位置信息、应用使用细节甚至健康数据,一旦用于训练,可能对敏感个人信息造成二次暴露。
其次是数据滥用风险,一旦缺乏严格监管,该数据可能被用于广告投放、行为分析等非透明用途,违背最初收集目的。再次是用户信任流失风险,用户可能因担心数据被过度利用而降低参与度,使整个反馈生态瘫痪,反而影响产品质量的提升。为了缓解这些问题,业内专家建议苹果应当为用户提供明确且易于操作的选择权,让用户能够清楚决定是否同意其错误报告数据被用于AI训练。同时加强数据脱敏和加密措施,确保敏感信息不能被模型直接检索或重现。透明化的隐私政策解读和定期第三方审计,也是恢复和维护用户信赖的重要环节。从更深层的市场和产业视角看,苹果的这一动作体现了科技巨头在AI竞争中的战略倾向。
数据作为AI发展的核心燃料,如何合法合规地最大化其价值,是每家公司都面临的挑战。苹果此前以保护用户隐私著称,但在AI领域的激烈竞争推动下,也开始逐步松绑数据使用限制。此举虽然有助于技术创新,但若处理不当,极可能引发反效果,激化用户隐忧和市场反弹。对广大用户而言,理清自身数据权益、掌握数据收集和使用的全貌越来越重要。面对巨头的政策变更,用户应主动了解相关条款,积极利用隐私设置,理智选择是否提交含敏感信息的错误反馈。同时,推动相关法规完善和实施,加强个人信息保护,也需成为社会共识。
苹果错误报告数据被用于AI训练事件,是隐私保护与技术进步之间的典型博弈,折射出科技发展背景下的伦理困境。它提醒我们,技术创新绝非无视用户权益的理由,企业必须在用户同意、数据安全和信息透明之间找到最佳平衡,赢得并保持用户的信任。从开发者及技术社区的角度看,保持反馈渠道的畅通与开放对软件生态健康至关重要。苹果若忽视用户和开发者的合理诉求,错误报告减少将直接影响Bug修复效率和产品稳定性,最终损害用户体验。未来,只有在尊重用户自主权和数据隐私的基础上,推动智能技术的应用,才能实现共赢。总结来看,苹果将错误报告数据纳入AI训练范畴,既是技术进步的体现,也暴露了隐私保护不足的短板。
面对公众的疑虑和反对,公司应更加透明与负责,完善用户选择机制,切实保障敏感信息安全。与此同时,用户自身也需要提高数据保护意识,主动管理隐私权限。随着人工智能的不断普及和应用深化,如何在创新与隐私之间找到和谐点,将成为科技行业亟待解决的重要课题。