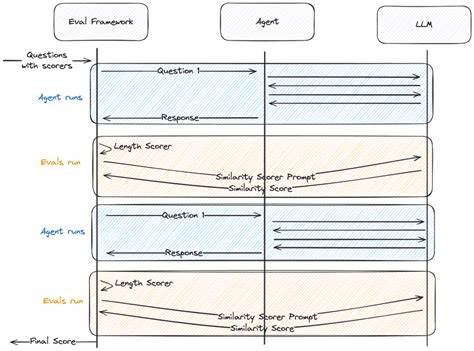
随着人工智能技术的飞速发展,智能代理已经越来越广泛地应用于各类场景,包括客服、医疗诊断、金融分析以及自动化运营等领域。在智能代理的研发和优化过程中,评估测试环节起到了至关重要的作用。如何正确评估智能代理的表现,成为了开发者和企业关注的焦点。本文阐述为何只有开发者自己编写的评估测试才是智能代理测试中最具价值的标准,以及如何有效构建符合实际需求的评估体系。 智能代理通常依赖于大规模语言模型(LLM)或其他人工智能算法,其表现往往与具体应用场景密切相关。现有市场上虽存在大量预设的评估指标和工具,但这些通用评估往往难以完全覆盖代理所面临的特殊业务逻辑、用户需求和交互习惯。
当开发者依赖于外部或标准化的评估方式时,所获得的结果可能无法真实反映智能代理在特定环境下的可靠性和表现。 自主设计评估测试具有明显优势。首先,开发者最了解代理的目标和使用情境,能够基于自身业务逻辑设计更贴合需求的测试情景和评估标准。这样的评估不仅考察模型对标准问答的应答,还能测试模型对复杂场景、多轮对话以及异常输入的处理能力。其次,自定义评估允许持续迭代优化。随着代理功能扩展和业务需求变化,评估内容也能实时更新,保持测试的相关性和有效性,避免停留在静态和过时的指标体系中。
另一个关键优势是对模型安全性、公平性和伦理风险的专属把控。智能代理在实际应用中可能面临偏见、歧视、错误信息传播等问题。公共评测标准虽然涵盖偏见检测等内容,但无法针对特定行业或用户群体调整检测参数和重点。自主评估可根据目标用户和运营环境,量身定制偏见或不当行为的识别机制,有效降低潜在风险。 打造高效的自主评估体系需要结合多维度指标。除了常规的准确率、召回率、响应速度等指标,开发者应增加情感识别、用户满意度模拟、上下文理解能力等综合性能测试。
通过模拟真实用户交互场景,及时捕捉模型在自然语言理解与生成方面的不足。此外,测试流程应纳入错误分析与反馈机制,帮助团队对症下药,推动模型性能和安全性的双重提升。 现代智能代理研发平台也开始重视赋能开发者自定义评估工具。例如部分平台提供了灵活的Agent Simulation模块,允许用户创建多变的测试环境和场景,生成丰富的模拟数据用于性能验证和压力测试。LLM Observability功能则帮助用户实时监测模型响应的时延、行为变化和用户体验,结合自主设计的评估用例,实现对代理整体表现的精准洞察。 总结来看,智能代理测试环节中的评估机制并非越通用越好,关键在于是否贴合实际使用需求。
只有开发者基于自身业务特点和目标,亲自设计和执行评估测试,才能有效识别模型优势与短板,确保代理在现实环境中表现优异并持续优化。围绕自主评估进行科学规划和实施,已成为智能代理技术可靠落地的必备保障。未来,随着AI生态的日益完善,更多个性化、定制化的评估方案将会涌现,助力智能代理迈向更加智能和安全的新时代。 。









