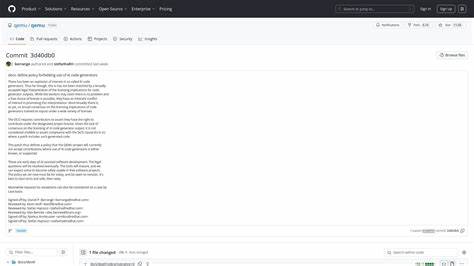
近年来,人工智能技术迅速崛起,尤其是在自动生成代码领域展现出强大潜力。许多开发者开始利用AI代码生成工具提升开发效率,借助智能助手编写复杂程序。然而,随着这一趋势的普及,开源社区对AI生成代码的态度也日益审慎。QEMU项目作为著名的开源虚拟机管理程序,其近日明确宣布禁止接受AI生成的代码贡献,引发广泛讨论。QEMU的这一政策体现了开源项目面对AI代码时的法律和道德困境,为其他项目提供了重要借鉴。开源软件的核心理念在于版权清晰和贡献者责任的可追溯性。
QEMU采用的Developer’s Certificate of Origin(DCO)协议要求贡献者保证提交的代码是“由本人原创”且“拥有合法的版权”,以确保代码来源的透明和可靠。但AI生成代码在版权归属上存在天生难题。目前全球多数司法管辖区尚未明确承认AI自动生成作品拥有版权,这使得AI代码难以满足DCO中“人类作者”这一基本要求。换言之,AI生成的代码缺乏明确的法律主体,使得贡献者无法像提交传统手写代码那样诚实声明其原创性。此外,AI模型的训练数据包含海量开源代码,且涵盖多种许可证。虽然现有的代码相似度检测技术能够一定程度降低代码许可冲突的风险,但仍无法彻底排除潜在的版权侵权隐患。
AI生成代码的复杂来源和可能的隐含版权争议,给开源项目带来了许可合规上的巨大不确定性。除此之外,AI生成代码的质量和安全性也令维护者担忧。AI工具经过大量公开源码训练,有时会无意重复或拼凑已存在代码片段,甚至带入漏洞或不适用的逻辑。开源项目在保护软件质量和安全的责任驱使下,必须加强对AI贡献代码的严谨审查。此次QEMU的明确禁令体现了维护版权安全和项目健康的坚定立场,也暗示开源社区对AI代码的接受仍须谨慎权衡。面对这些挑战,开源项目如何合理接纳AI生成代码成为亟需解决的问题。
首先,必须提升AI生成代码与已有代码片段的比对技术。现有商业工具具备较强能力,但推动开源社区研发开源比对工具不仅有助于共享资源,也能让更多项目自主管理AI代码合规风险。其次,增强AI代码的透明度和可追溯性至关重要。SPDX(软件包数据交换格式)等开源许可规范应快速增设AI代码专用标识,使得自动化系统能识别和管理AI贡献,促进责任归属的清晰化。再者,DCO协议本身也面临升级压力,如何合理调整“人类作者”的声明以反映AI时代的现实,是行业亟需讨论的议题。尽管DCO以往因其简单性和通用性获得广泛采纳,对其进行重大修改可能影响庞大生态的稳定,因此短期内更现实的做法是通过完善项目层面的说明文件,明确贡献者在申明“原创”时的合规要求,形成统一且易理解的框架。
Linux基金会作为DCO的发起者,理应引导行业制定针对AI生成代码的指导原则,包括定义最低接受风险标准,平衡法律安全与开发效率。不同项目根据自身风险容忍度和发展策略,能够有序选择对AI代码的适用政策,同时维护整个开源生态的健康发展。在技术层面,AI生成代码的未来也取决于AI模型自身的开源程度和训练数据透明度。当前部分AI模型及其训练素材公开度不足,限制了开源社区对其合法性的全面评估。推动开源AI模型的发展,公开训练数据来源,可能缓解版权法律风险,为开源软件的AI辅助开发奠定更坚实基础。值得注意的是,开源社区必须警惕AI代码带来的多重风险,包括潜在版权纠纷、代码质量下降以及一旦出现安全漏洞时责任不明。
完善代码审查机制,强化贡献者声明内容,设立专门负责AI代码复核的团队,将极大提高项目的抗风险能力。总而言之,QEMU禁止AI生成代码的政策是当前阶段对法律和伦理风险的严格回应,也体现了开源界对AI时代挑战的主动防范。未来,伴随着法律体系对AI作品确认权利归属的逐渐完善、AI检测技术的进步以及开源社区对相关协议的合理调整,开源项目将能够探索出切实可行的接纳AI生成代码的方案。只有在确保版权合规、人类作者责任明确和代码质量安全的前提下,AI生成代码才能真正成为开源软件发展的助推器。开源是一场全球协作的事业,AI工具无疑会成为开发者的重要伙伴,但这需要整个社区共同努力,建立信任、规范和技术保障,方能实现AI与开源的健康共赢。未来已来,开放与创新的路上,合理包容与规范运用AI代码贡献,将是开源社区持续繁荣的关键所在。
。