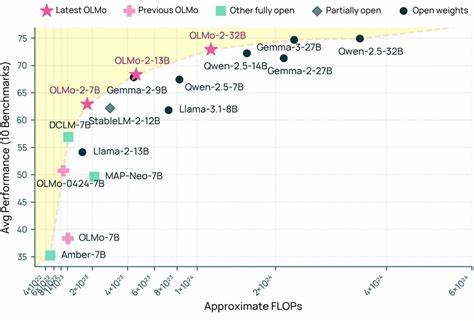
近年来,随着人工智能技术的迅猛发展,特别是大型语言模型(LLM)的广泛应用,推动了自然语言处理领域的跨越式进步。在这一领域,诸如OpenAI的GPT系列等闭源模型凭借其强大的性能赢得了全球关注,但开放性和透明度的缺失也引发了学术界和工业界的反思。作为回应,艾伦人工智能研究所(AI2)推出了OLMo系列全开放语言模型,以实现技术的共享与共建,代表着人工智能开放生态的全新高度。OLMo模型的最新版本OLMo 2 32B,更是首次在一系列多技能学术基准测试中,全面超越了GPT3.5-Turbo和GPT-4o mini,成为现代开源语言模型中的佼佼者。 OLMo的诞生源于AI2对开放科研理念的执着追求。与其他语言模型封闭训练、数据和代码资源的做法不同,OLMo从数据采集、模型训练代码到评测过程均完全开源,确保研究人员和开发者可以自由访问、复现和改进。
这种端到端的透明训练流程不仅提升了模型性能的可信度,也促进了学术界对语言理解和生成机制的深入研究。OLMo 2系列包括1B、7B、13B和32B四种规模,覆盖了从轻量级快速迭代到高性能复杂任务处理的多样需求,满足不同研究和应用场景。 在技术细节上,OLMo 2 32B是该系列中的旗舰产品,基于大规模6万亿训练token打造,采用了先进的训练架构及流水线技术,并整合了Tulu 3.1后训练策略,显著增强了模型在多语言、多任务上的表现和稳定性。通过持续的中间检查点发布和公开评测代码,研究人员能够实时监控训练进展并分析模型演变,极大地提升了模型研发的科学严谨性和开放程度。 与市面上主流闭源模型相比,OLMo 2 32B表现出卓越的学术能力。在多个具挑战性的多技能基准测试中表现优异,涵盖了语言理解、推理、代码生成和对话等多维度任务,其准确率和综合能力均超越了GPT3.5-Turbo和GPT-4o mini等广为认可的顶级模型。
这表明全开放模型不仅能够缩小乃至超越商业闭源模型的性能差距,更在透明性和可控性方面具有不可替代的优势。 OLMo 2的中小规模模型同样表现出色。7B和13B版本在英语学术评测中与Meta和Mistral等开放权重模型旗鼓相当,既保证了研究的可重复性,也为更多科研机构提供了高效的实验平台。1B模型则以灵活轻便著称,为学术界和独立开发者带去快速迭代和本地部署的可能,促进了社区参与和模型多样性的发展。 OLMo项目的核心理念在于坚守“真正的开放性”,不仅仅局限于简单地开放模型参数,更强调数据来源、模型架构、训练流程、评估标准乃至代码实现全方位透明。这一理念推动了人工智能领域的科研民主化,打破了商业巨头对最前沿技术的垄断,实现了技术资源共享和创新加速。
研究人员可以基于OLMo代码和数据自由开展实验,验证假设,甚至建立全新的模型变体,为学术交流和工业应用注入新的活力。 此外,OLMo项目的开放生态也大力支持全球多语言和多文化研究。训练数据涵盖丰富的语言、多领域内容,帮助模型实现多任务泛化和跨语言理解,推动翻译、教育、医疗等领域的智能化发展。AI2还提供完善的文档、技术报告与在线社区,搭建了一个涵盖开发者、研究人员与用户的互动平台,促进技术的普及和深化。 在未来,OLMo的开放策略预计将引领更多创新研发。随着开放社区的不断壮大,更多贡献者将共同参与模型改进和任务扩展,推动模型在对话系统、复杂推理以及特定专业领域的定制化应用。
此外,开放训练代码和数据还有助于提升模型安全性和公平性,激励更加负责任的人工智能研发态度。 综上所述,OLMo语言模型及其最新的OLMo 2 32B版本,不仅以卓越的技术性能惊艳业界,更树立了开放人工智能的典范。它打破传统AI研发的壁垒,带来了更高透明度、更强互操作性和更广泛的参与可能。作为人工智能研究与应用的重要里程碑,OLMo的出现将进一步推动全球语言模型技术的民主化与多样化发展,成为连接技术创新与社会进步的桥梁,激发未来更多无限可能。