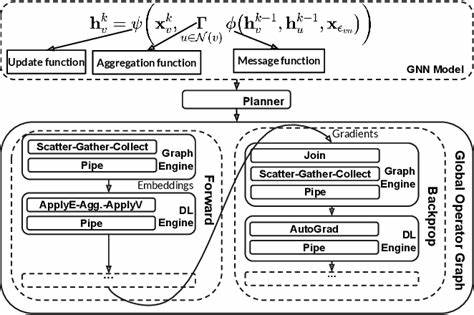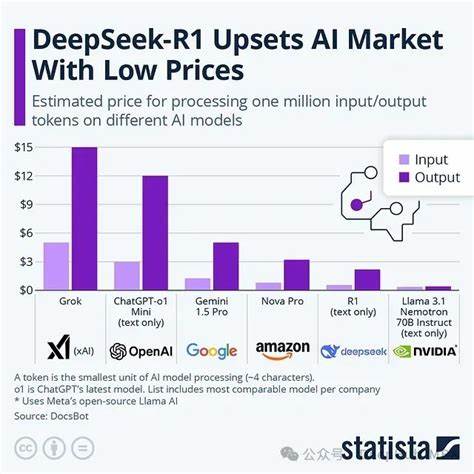
在当今人工智能和自然语言处理技术快速发展的背景下,模型处理更长上下文的能力成为衡量其智能水平的重要标准。尤其是在大型语言模型领域,如何突破传统上下文窗口的限制,实现对更长文本的有效理解和记忆,成为研究的前沿方向。Tavkhid方法便是在这一背景下提出的一种创新技术,旨在为DeepSeek-R1模型带来超越128K令牌限制的持久记忆能力,从而极大拓展该模型在信息检索、文本生成、智能问答等领域的应用潜力。 Tavkhid方法的核心理念是通过模拟持久记忆机制,打破传统Transformer架构在上下文规模上的桎梏。当前大部分深度学习模型的上下文窗口受限,通常在几千至数万令牌之间,甚至较大的模型如GPT系列也难以支持超过10万令牌的长文本处理。这种限制对需要深入理解长篇文档、连续对话或复杂任务的应用场景造成了瓶颈。
DeepSeek-R1引入的Tavkhid方法则通过一套独特的记忆重建和递归融合机制,使模型能够以更高效的方式存储和检索超长上下文信息,实现持久化的记忆管理。 具体来看,Tavkhid方法利用一种模拟记忆的策略,将长文本拆分为多个语义模块,并通过深层的重建算法将这些信息压缩并编码成可重复调用的记忆体。这种记忆体不仅可以被模型快速引用,还能随着输入的动态变化进行更新和优化,极大地增强了模型对长期信息的掌控能力。相比传统的注意力机制,Tavkhid的设计更具灵活性与扩展性,使DeepSeek-R1能够有效处理128K令牌以上的输入长度,而不会遭遇计算资源的急剧增长或性能的显著下降。 持久记忆的实现对于提升整个自然语言处理系统的智能水平具有深远意义。首先,在文本理解层面,模型能够在更大范围内建立联系,提升对上下文关联的感知和推理能力。
对于跨章节、跨文档的信息综合,Tavkhid方法使模型能更准确地捕捉主题发展和细节变化,进而生成更连贯和具逻辑性的回答或总结。其次,在交互体验方面,持久记忆能够保存用户信息和对话历史,支持连续多轮对话,使人工智能助手更贴近人类的认知模式,提升交互的自然度和效率。DeepSeek-R1凭借Tavkhid方法在这方面展示了其作为一个智能对话系统的巨大潜力。 除了理论意义,Tavkhid方法在实际应用中也表现出了令人瞩目的优势。它为大规模文本检索与分析提供了技术基础,支持从浩瀚文献、数据库或在线资源中提取精准且深度的信息支持。尤其在法律咨询、医学诊断、科研文献综述等需要处理海量专业文本的领域,长上下文的支撑显得尤为关键。
此外,该方法还有助于人工智能创作,如长篇故事、剧本或复杂代码的自动生成中,实现章节间的风格统一和内容连贯。 DeepSeek-R1结合Tavkhid方法的整体架构也呈现出高度模块化和灵活性的特点。该系统不仅包含强大的记忆管理单元,还配备了多层次的语义分析引擎和优化的令牌编码机制。这使得模型能够在保持运行效率的同时,动态调整记忆嵌入的粒度和范围,兼顾细节捕捉与全局理解。与此同时,系统在硬件资源利用与能效方面也做了优化,保证了在处理海量数据时的稳定性与响应速度。 随着人工智能技术的不断进步,长期记忆和大规模上下文处理成为促进机器智能迈向更高层次的关键。
Tavkhid方法的创新不仅突破了传统限制,也开辟了更多可能性,促进了AI在复杂任务中的实用化。未来,结合更多联邦学习、多模态融合以及自监督学习等前沿技术,持久记忆机制将更加强大和智能,助力人工智能系统更好地理解世界和人类需求。 总结来看,Tavkhid方法作为DeepSeek-R1的核心突破,为持久记忆的实现提供了全新的解决方案。它有效扩展了模型的上下文处理界限,使得大规模文本分析和连贯生成成为可能。对推动智能文本系统发展、优化用户体验以及深化AI应用领域都具有重要价值。随着相关技术和生态的不断完善,相信Tavkhid方法将在未来人工智能产业中扮演越来越关键的角色,助力实现更智能、更高效的人机交互和信息处理。
。