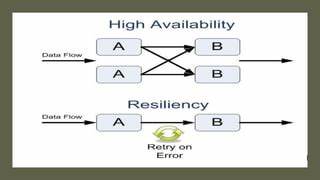
在现代互联网应用和企业级服务中,数据库的高可用性和弹性成为保障业务连续性和用户体验的核心要素。随着数据量的快速增长和访问需求的日益复杂,水平扩展(Horizontal Scaling)成为数据库架构设计的关键路径。市场上主要有两种数据库架构方案:应用层分片(Application-Level Sharding)和分布式SQL(Distributed SQL)。本文深入探讨这两种架构的工作原理、优势与劣势,同时运用概率论解析它们在可用性和弹性上的显著差异,帮助技术决策者做出科学、合理的选择。 应用层分片是一种基于领域知识的数据分区方式,通常由应用程序负责将数据划分至不同的数据库实例,每个实例运行在独立服务器上。比如,用户数据可能根据ID范围被分散到多台服务器上,服务器1负责客户A至F,服务器2负责客户G至L,如此分布。
这种做法的优点在于简单直观,可以针对特定业务需求作出定制化调整,实现一定的负载分担。然而,其弊端也十分明显。由于每个分片服务器独立处理其所属数据,若其中任何一台服务器发生故障,该分片上的全部数据便不可用,严重影响整体系统的可用性。更关键的是,应用层需要承担复杂的路由逻辑、跨分片事务管理、重新分片与负载均衡等任务,增加开发复杂度和维护成本。 从概率论的视角来看,假设某云服务供应商的虚拟机实例每月可用性为99.9%,即单个节点故障概率极低。若一个系统由六个节点构成,每个节点独立承担一个分片,并要求所有分片全部正常工作才能保证系统可用,那么系统整体的可用性是每个节点可用率的乘积,将约为99.4%。
这也就是说,尽管单个节点很稳定,但整体系统面对节点故障的敏感性极强,任何一个节点的掉线都会造成服务不可用,这远低于单节点的高可用水平。 相较之下,分布式SQL架构设计了一套更为先进的横向扩展与容错机制。它在逻辑层面提供了一个整体数据库视图,自动分片并且在每个分片上维护多个副本。多副本间通过法定数量(quorum)机制来实现强一致性和故障容忍。在实际部署中,数据副本会被分布在不同的可用区(Availability Zones),确保即使某一区域发生中断,其他副本仍能承担服务请求,保证整体数据库持续可用。 概率论中的二项分布可以很好地描述这一现象。
设节点故障概率不变且各节点独立,数据复制因子(Replication Factor)为三时,系统可以容忍其中一个节点失效而不影响服务。只有当两个或更多节点失效且影响到同一分片的超过半数副本时,服务才会不可用。计算统计结果表明,六节点、复制因子为三的分布式SQL系统整体可用性达到99.998%,远远超过应用层分片系统。同理,进一步提升复制因子至五,节点增加到十个,可用性更可达到99.99999%,接近七个九的水平,显示了极致的高可靠性。 这两者在商业应用中所体现的重要性尤为明显。一家金融支付平台若采用应用层分片架构,任何一个节点的不稳定都会导致部分用户数据不可访问,影响交易连续性,损失数百万美元的潜在收入和用户信任。
分布式SQL架构的高可用性则显著降低上述风险,保证服务在硬件故障、区域中断等情况下依然稳定运转。 除了高可用性外,分布式SQL在自动路由、负载均衡及跨节点事务管理方面也大大简化了开发流程,缩短产品交付时间。与之相对的是应用层分片繁琐的路由逻辑、跨分片一致性保证难题及频繁的运维复杂性,需要团队拥有丰富的专业技能和大量人力投入。 在架构选择上,企业应充分权衡技术复杂度、成本、业务连续性需求及可扩展性潜力。应用层分片虽便于初期快速上线,适用于数据隔离明显、跨分片交互较少的场景,但随着业务增长,其固有的可用性瓶颈和复杂维护风险逐渐显露。分布式SQL通过内置副本和共识算法,达成了高弹性和持久一致性,是面向未来、追求高稳定性平台的理想选项,尤其适合要求实时性、事务一致性和大规模并发访问的核心业务。
最终,现代数据库架构的发展趋势显示,结合概率论等数学方法科学评估系统可用性的必要性日益增强。分布式SQL代表了一个迈向自动化、自愈性和高度可靠架构的方向。在这个体系下,数据不仅被智能分布和复制,而且系统能够自动感知节点故障,动态调节运行状态,降低人为干预,实现真正的弹性计算。 总而言之,分片架构与分布式SQL架构之间的数学背后显现出巨大的可用性差异。通过精细的概率计算和实际业务需求结合,分布式SQL无疑成为构建高可用、高弹性数据库系统的优选。企业若希望在竞争激烈的数字时代保持领先,保障关键数据服务的连续性和稳定性,必须用科学、严谨的视角审视基础架构的设计选择。
分布式SQL的优势,正是支撑未来数字经济发展的坚实基石。