Google Bigtable作为一款高性能、可扩展的分布式NoSQL数据库,广泛应用于云计算领域,特别是在需要处理海量数据和高并发访问的场景中表现卓越。Bigtable兼容Cassandra和HBase,拥有每日处理数十亿查询请求和管理数十个Exabyte级别数据的能力。随着用户需求的不断增长,提升数据读取效率成为Bigtable团队持续关注的重点方向。最近,Bigtable单行读取吞吐量获得了高达70%的提升,这不仅再一次彰显了其核心技术的领先地位,也极大增强了用户面对复杂业务需求时的响应能力和成本效益。提升单行读取性能为何如此重要?单行读取操作是许多关键业务的核心,如实时风控、用户画像查询、个性化推荐等,要求系统在极低延迟下快速返回单个数据行结果。提高单行读取的吞吐能力意味着系统可以承载更多并发查询,极大降低因节点扩容带来的硬件成本。
同时,保持低延迟对于提升用户体验和满足流式数据处理需求具有决定性意义。Bigtable团队基于一系列前瞻性的研究和技术创新,通过多层面突破实现了此次显著的性能提升。首先,在缓存机制上做出了创新性改进。传统的缓存策略通常以数据块为单位进行缓存,以减少磁盘I/O并提高访问速度。然而,对于热点行的频繁查询,这种块级缓存存在一定的冗余消耗和CPU开销。针对这一问题,Bigtable引入了行缓存机制,不再单纯缓存整块数据,而是以稀疏表示方式,仅存储被查询的行内数据片段。
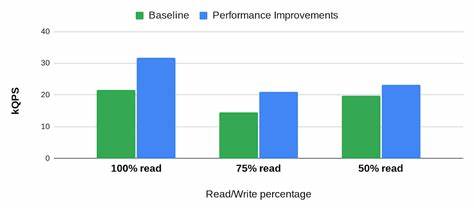
这种针对性缓存大幅减少了CPU处理负载,提升了缓存命中率,进而实现单行读取性能提升约25%。此创新不仅优化了缓存效果,还有效平衡了行缓存和块缓存之间的资源竞争,通过智能驱逐算法保证了缓存空间的最优利用,确保应对繁多不同查询模式的适应性。同时,在单行读取操作的路径优化上,Bigtable团队深入剖析了处理流程中的关键瓶颈。鉴于单点读请求仅需访问单个节点,团队去除了多节点RPC调用和复杂合并逻辑,优化了调度和执行效率,使得CPU资源分配更加精准。结合对点读过滤表达式的查询优化,将约50%的过滤表达式重写为更高效的形式,推动单行读取吞吐率提升12%。此外,调度器的智能改进也为性能提升贡献了力量。
Bigtable推出了基于应用配置的请求优先级系统,支持高、中、低三个优先级别,精准区分关键业务与后台分析作业,保障高优先级请求获得更快的响应和更高的调度权重。特别是在混合事务/分析处理(HTAP)场景中,该策略有效防止批量分析操作对单行读取的延迟产生负面影响,保障服务的稳定性与一致性。调度器还通过监控运行时间和动态插入让出点,令长时间运行的复杂操作与短小的单行读取请求交替执行,避免资源过度占用导致的排队等待,进一步降低了高优先级请求的等待时间。这种细粒度请求调度的引入,极大改善了系统负载均衡和响应速度。在实际应用中,这些技术改进已被多个大规模客户验证。例如,网络安全公司Stairwell利用Bigtable支撑复杂的威胁检测系统,处理包含数亿行、上千万列的巨大数据表,平均单行读取延迟低至1.9毫秒,最高不超过4毫秒。
其卓越的性能体现了Bigtable在极端数据规模下依然保持高吞吐、低延迟的能力。音乐流媒体巨头Spotify也将Bigtable作为关键支撑平台,支持其实时人工智能算法和基于大数据的推荐引擎。随着多个版本性能的迭代优化,Spotify实现了集群节点数量的显著削减,减少运营成本的同时提升了系统响应效率。用户反馈坦言,Bigtable性能升级带来的成本优势和稳定表现值得期待。从技术层面看,Bigtable持续通过综合基准测试分析访问模式,识别性能瓶颈,再辅以采样分析和动态配置,实现多维度的性能突破。行缓存和块缓存的有机协同、查询路径的剖析优化、调度机制的智能升级,共同铸就了此次性能大跃升。
在行业趋势层面,随着数据规模暴增和实时业务需求的提升,数据库系统必须在保持高吞吐的同时,兼顾低延迟和成本管理。Bigtable在这一挑战上以创新技术持续引领,通过供应商内核优化和用户级配置改进,赋能多样化场景。未来,Bigtable还将持续强化面向SQL查询的支持、增强实时统计功能以及引入更多自适应算法,进一步提升整体性能和用户体验。总之,Bigtable单行读取性能的70%提升不仅提高了每个节点的负载承载能力,更为广泛的云端业务带来了极大的性能弹性和经济效益。对于企业用户而言,这意味着能够在维持低延迟体验的同时,降低集群扩容需求和运维复杂度,释放更多发展空间。Bigtable正以技术创新为核心驱动力,引领分布式数据库迈向更高效、更智能的新时代。
。