在大型分布式服务环境中,传统的 Kubernetes 层 4 负载均衡机制在高并发、长连接和低尾延迟场景下会遇到显著瓶颈。Databricks 在其内部平台上面向 gRPC 与持久连接流量,采用了以客户端为中心、由控制平面驱动的智能负载均衡方案。通过实时服务发现、xDS 协议和内置于 RPC 客户端的策略,Databricks 能在不依赖 kube-proxy 的前提下,实现更均衡的流量分配、更低的尾延迟以及更高的资源利用效率。以下内容系统性地介绍该方案的背景、架构细节、工程挑战与实践教训,并提供可供其他团队借鉴的实施建议。 Kubernetes 默认负载均衡的局限性 Kubernetes 的默认流量转发依赖 CoreDNS 返回的虚拟 ClusterIP,以及节点上的 kube-proxy(通过 iptables、IPVS 或 eBPF)在内核层选择后端 Pod。该模式在大多数短连接或 HTTP/1 场景下表现良好。
但对于基于 HTTP/2 的 gRPC 等长期连接协议,这种在第 4 层仅在连接建立时做一次后端选择的方式会导致严重的流量偏斜。多个客户端复用少量长连接时,部分 Pod 可能被大量长连接锁定,从而承受不成比例的请求压力,产生高尾延迟和不稳定的性能表现。此外,kube-proxy 的负载均衡策略通常只支持轮询或随机选择,难以支持带权重、错误感知、地域亲和等更复杂的调度策略。 需求与设计目标 Databricks 的内部服务以 Scala 为主、服务间大量采用 gRPC 通信。这带来了两个关键需求:第一,需要按请求而非按连接做出路由决策,以缓解持久连接带来的负载集中问题;第二,需要在服务间共享可靠的拓扑与健康信息,以便在客户端实现更智能的调度策略。基于这些需求,Databricks 确定的设计目标包括客户侧的实时服务发现、低延迟的控制面推送、可插拔且简洁的调度策略,以及对外网网关(Envoy)的一致端点信息供给。
系统架构概览 Databricks 构建了一个轻量级的控制平面,称为 Endpoint Discovery Service(EDS),用于持续监听 Kubernetes API 中的 Service 和 EndpointSlices。EDS 将集群中的后端 Pod 列表、就绪状态、可用区信息等元数据抽象并以 xDS 协议的形式下发给订阅方。内部 RPC 客户端(嵌入在公司统一通信框架中)在建立连接时向 EDS 订阅依赖服务的端点变更,客户端随时维持一份最新的健康端点快照,并在每次请求级别做出负载均衡决策。与此同时,EDS 也向 Envoy 下发 ClusterLoadAssignment,保证外部流量网关与内部客户端使用相同的"事实来源"。 客户端调度策略 在 Databricks 的实践中,简洁而有效的调度策略往往优先被采用。Power of Two Choices(P2C)成为默认策略:客户端随机挑选两个后端,然后选取当前活动连接数或负载较低的一方处理请求。
P2C 在实现复杂性和负载均衡效果之间取得了良好平衡,能够显著缓解因持久连接带来的流量不均。除了 P2C,平台还支持地域/可用区亲和策略,优先选择局域可用区的后端以减少跨区网络开销和延迟;当本区无足够健康容量时,算法会智能溢出到其它可用区,兼顾低延迟与高可用。 将调度逻辑直接内置到 RPC 客户端带来了关键优势。客户端可以获得请求级别的上下文信息,从而做出更加细粒度和语义相关的路由决策;此外,跳过 DNS 缓存和 kube-proxy 的依赖,使服务发现路径更简洁、延迟更可控。Databricks 借助其统一的 Scala 通信框架,将该能力快速覆盖到大部分内部服务,缩短了推广成本与运维开销。 xDS 与 Envoy 的集成 为了保证对外入口流量与内部客户端使用一致的端点视图,EDS 对外提供 xDS 的 Endpoint Discovery(EDS)接口,向 Envoy 发布 ClusterLoadAssignment。
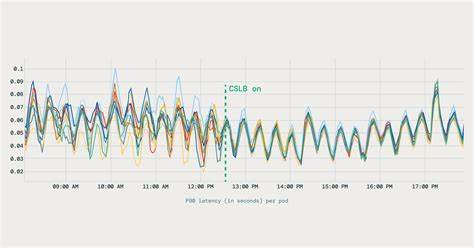
这样一来,边缘网关和内部服务共享同一套端点元数据与健康策略,避免了不同路径下不一致的路由决策。通过这种方法,Databricks 能让 API 网关级别的负载分配与客户端层级的调度保持一致性,利于故障排查和全局流量优化。 效果与业务影响 上线客户端负载均衡体系后,Databricks 在多项关键指标上获得明显改善。后端请求分布更加均匀,单 Pod 的 QPS 方差显著降低,原来因连接粘性导致的少数 Pod 过载问题基本消失。延迟分布也趋于稳定,P90 和 P99 指标出现下移,尾延迟问题得到缓解。由于资源利用率提高,部分服务的 pod 数量得以削减,某些场景下总体 pod 数量降低约 20%,从而释放了计算资源并降低了成本。
工程挑战与应对策略 在实践过程中,团队也遇到了一些意料之外的问题。客户端主动调度流量意味着新启动的 Pod 会立即开始接受请求,这在之前的连接粘性模型中较少发生,从而暴露出冷启动或初始化开销问题。为此,Databricks 在调度层引入了 slow-start 的流量缓坡机制,并在客户端层面偏向于避免将流量分配给高错误率或健康评分较差的实例,以确保新 Pod 有充足的暖身时间。 另一个挑战来源于对运行中指标做直接路由决策的尝试。团队曾探索基于 CPU 或其他资源指标的"按需路由"策略,但发现监控系统的采样频率和可靠性往往不足以作为真实时的负载指示,且这些指标常常是滞后的。因此,Databricks 最终选择依赖更可靠的健康检查和连接级别的负载度量,而不是简单地根据资源指标做流量倾斜。
替代方案评估与取舍 在设计阶段,团队评估过多种替代方案。Kubernetes 的 headless service 可以通过 DNS 给客户端返回后端 Pod 列表,从而绕过 kube-proxy 的连接选择。但 DNS 本身存在缓存和元数据匮乏的问题,难以完全满足对权重、地域信息和实时健康状态的需求。Service Mesh(例如 Istio)通过 sidecar+Envoy 的模式提供强大的 L7 能力,但在 Databricks 的大规模部署环境下,sidecar 带来的运维复杂性、资源开销以及对客户端语义的感知不足使其并非最佳选择。Databricks 的 Scala 优势和统一的通信框架也降低了采用代理无代理(proxyless)客户端库的门槛,因此最终选择了轻量级、可控性更强的客户端驱动模型。 实践建议与工程落地要点 对于希望在自身环境中实施类似方案的团队,有若干工程要点值得参考。
首先,服务发现控制平面应具备高可用与低延迟的订阅推送能力,确保客户端能在短时间内感知拓扑变化。其次,把负载均衡策略实现为可插拔模块,既能提供一个统一的默认策略(例如 P2C),又能按需为特定关键服务定制更复杂的策略。再次,要考虑冷启动与热身策略,避免新实例被立即打爆。监控与可观测性也非常重要,需要收集请求级别的延迟分布、错误率、连接数等多维指标,以便评估策略效果并进行回滚或调整。 安全性与合规性考量 在控制平面向客户端下发端点信息时,必须保证数据的完整性与机密性。采用双向 TLS、鉴权以及最小权限原则可以降低被动攻击与数据泄露风险。
Databricks 在内部结合已有的证书分发和安全基础设施,确保了控制面与客户端之间的安全信道。此外,审计日志和变更记录对于排查生产事故以及满足合规审计要求也不可或缺。 未来方向与技术扩展 随着跨地域、多集群部署的扩展,Databricks 正在探索将该模型扩展到跨集群和跨区域场景,以实现全球调度和更高层次的容灾能力。为 AI 与异构工作负载提供的更细粒度加权调度也是一个重要方向,通过为不同类型的后端实例赋予不同权重,可以更合理地分配昂贵的 GPU 或特定硬件资源。另一个值得关注的方向是将实时负载预测与路由决策结合,通过更前瞻性的流量预测来进一步优化尾延迟与成本。 总结与实践价值 Databricks 的经验表明,在大规模、以 gRPC 为主的服务网格中,简单而高效的客户端负载均衡能够在性能和运营成本之间取得良好平衡。
以 xDS 为基础的实时服务发现与控制平面,使得客户端可以在不依赖 kube-proxy 的情况下获取最新的端点元信息;内置于 RPC 框架的可插拔调度策略,如 P2C 和区域亲和,使得请求级路由成为可能,显著降低尾延迟并提升资源利用率。对于拥有统一通信框架或愿意维护客户端库的组织而言,代理无代理的客户端负载均衡是一个值得重点考量的方向。随着多集群和 AI 负载的演进,该模式仍有广阔的优化与扩展空间。希望这些实践经验能为正在面临类似挑战的运维与平台工程团队提供参考与思路。 。