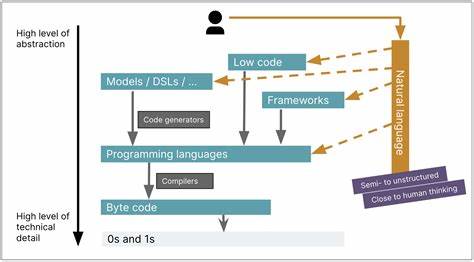
近年来,随着人工智能技术的迅猛发展,大型语言模型(Large Language Models, LLMs)成为推动软件开发范式变革的关键力量。它们不仅极大地提升了编程的抽象层次,而且首次将非确定性的特点引入了传统的软件开发流程,带来了纵向和横向的双重创新。这种变化堪比从汇编语言到高级语言的巨大飞跃,甚至表现出更深远的影响。 传统上,编程语言的发展一路向上探索抽象层次。以汇编语言为例,程序员需要管理寄存器和机器指令,关注每一步具体的硬件操作,而这极大地限制了开发效率和表达能力。高级语言的出现允许我们使用更接近人类思维的语义表达算法逻辑,比如条件判断、循环和数据结构,使编程更易于理解和维护。
虽然高级语言带来了抽象层级的提升,但它们依然是确定性的,意味着同样代码在相同输入下会产生完全相同的输出。 而大型语言模型带来的变化不仅体现在提高抽象层次。它们通过自然语言的交互接口,允许开发者用更直观的方式向机器表达意图,消除了传统代码书写的许多限制。更重要的是,这种交互方式引入了非确定性的特性,模型的输出依赖于复杂的概率分布,每次生成都可能略有不同。这种“横向”的变化对编程思维和流程提出了新的挑战。 首先,大型语言模型的使用代表着编程范式的转变:从直接编写静态代码转向更具合作性和动态性的语言交流。
开发者不再是机器指令的直接发出者,而是以自然语言提示的形式与模型对话,通过多次迭代完善结果。这种过程类似于人与人之间的讨论和协作,极大地丰富了人机交互的可能性,但也带来了不确定性和不可重复性的难题。 这种非确定性的本质意味着传统的软件开发工具链,如版本控制系统,对提示语或模型输出的管理需要重新设计。提示语同样成为“代码”状态下的重要内容,但相同的提示语可能因模型更新、服务器状态或调用环境不同产生差异。这就要求开发者设计全新的测试和调试方法,以适应结果的变动性,同时保证软件的质量和稳定性。 大型语言模型提供了前所未有的抽象表达力。
通过输入简单的自然语言描述,模型可以自动生成复杂的代码片段、框架甚至完整模块,极大地节约了人力成本和时间。此外,这还鼓励开发者将更多精力投入到设计和架构层面,而将重复性的编码工作委托给模型完成,实现生产力的质的飞跃。 然而,这场变革并非没有风险。非确定性的模型输出可能导致隐蔽的错误和漏洞难以检测,模型自身的知识截止于训练数据时期,存在过时或错误的风险。此外,过度依赖模型生成的代码可能削弱开发者的基础技能,对代码的深度理解和维护提出了一定挑战。 为了有效利用大型语言模型,新兴的开发实践不断涌现。
例如,更加注重与模型的提示工程,优化输入的设计来获得更准确和稳定的输出。结合人机协作的检查机制,融合自动化测试与人工复核保障代码质量。同时,架构设计师也开始思考如何将非确定性作为设计考量,希望构建能容忍一定波动性和不确定性的系统,提升整体的弹性和适应能力。 此外,大型语言模型的引入促进了敏捷开发理念的深化。传统敏捷强调快速迭代和持续反馈,而在非确定性的编程环境下,反馈循环不仅限于代码本身,更涉及模型行为的观察和调整。这要求团队具备更高的跨领域能力,融合人工智能和软件工程知识,共同面对不断变化的挑战。
全球范围内,理论界与业界对这一趋势的关注日益增加。各大技术公司和开发社区纷纷投入资源,研究如何在保证稳定性和可维护性的前提下,最大化利用大型语言模型的潜力。开源项目与商业产品结合,形成生态圈,加快整个产业的转型步伐。 总结来看,大型语言模型不仅在提升抽象层次上实现突破,更在非确定性这一维度开辟新境界。这一“纵向与横向”的双重演进,将深刻影响软件开发的未来形态。从长远角度看,开发者与智能模型合作的新时代正徐徐展开,必将催生更多创新的工具、方法以及思考方式,推动整个行业迈向更高效、更智能的未来。
。