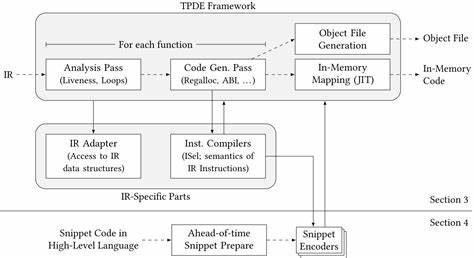
背景与价值 随着即时编译器 JIT 在运行时编译效率与启动延迟之间权衡的问题日益重要,研究界与工程界都在探索更快速、更轻量的代码生成器。TPDE 是由慕尼黑工业大学研究人员开源的单遍代码生成后端,设计目标是极低的编译延迟和在 -O0 场景下仍能产生可接受代码质量。TPDE 不追求覆盖 LLVM 全量指令集,而是专注最常见路径,这使得它非常适合用作基线 JIT 后端。将 TPDE 与 LLVM 的 ORC(On-Request Compilation)框架集成,能够在保留 LLVM 强大生态与优化能力的同时,获得显著的编译时缩短,适用于即时启动、REPL、快速反馈循环等场景。 核心思路与基本集成 LLVM ORC 提供了灵活的组件化接口,可以通过替换默认的编译器实现来接入自定义后端。常见的便捷入口是 LLJITBuilder。
使用 LLJITBuilder 的 CreateCompileFunction 回调,可以将 TPDE 封装为符合 IRCompileLayer::IRCompiler 接口的编译器对象。基本流程包括为每个 LLVM Module 调用 TPDE 的 compile_to_elf,将生成的机器码写入内存缓冲区,并以 MemoryBuffer 的形式交给 ORC 后续的加载与链接管线。 以伪代码描述封装类的关键部分可以帮助理解实现要点。构造函数通过目标三元组初始化 TPDE 编译器实例,operator() 接收 Module,创建输出字节缓冲区,并调用 compile_to_elf。如果 TPDE 编译失败,则返回错误,成功则返回指向二进制内存的 MemoryBuffer 引用。此处的实现无需修改 LLVM 源码,可以与官方发行版的 LLVM 19/20 一起工作。
回退机制:为何需要同时保留 LLVM TPDE 的设计哲学使它在常见类型和指令上表现优异,但并不覆盖所有 LLVM IR 特性。高级矢量指令、某些复杂浮点类型或不常见的指令序列可能会导致编译失败。生产环境中,为了保证功能完备性,通常会实现一个透明的回退机制:当 TPDE 无法处理某个模块或函数时,交给 LLVM 的内置后端(例如 SimpleCompiler 或 TargetMachine)来完成编译。这种混合策略能兼顾性能与兼容性,绝大多数模块走 TPDE 快速路径,仅少量模块进入较慢的 LLVM 路径。 回退实现要点包括保留 JITTargetMachineBuilder 的信息,以便在回退路径动态创建 TargetMachine,然后用 SimpleCompiler 对 Module 完整编译。这个方案天然线程安全且对开发者友好。
日志记录对排查哪些 Module 被回退非常有用,可以打印模块名和失败原因来评估 TPDE 的覆盖率。 并发编译的实现与陷阱 ORC 原生支持并发编译,但当自定义编译器中包含非线程安全的第三方组件时,需要格外处理。TPDE 的 compile_to_elf 目前不是线程安全的,直接在并发编译场景中共享单个实例会导致竞态和崩溃。解决方案是将 TPDE 编译器实例变为线程本地存储(thread_local),在每个线程第一次访问时初始化自己的 TPDE 实例。这样可以把实例数量限制为活跃编译线程数,避免为每个编译任务创建新实例带来的开销。 并发时还要注意对共享缓冲区的保护。
为避免多个线程同时修改同一个容器,应该使用互斥体(mutex)或其他并发容器来管理存放编译产物的 vector。只在必要的最小临界区内加锁,以降低锁竞争对性能的影响。 在使用 LLJITBuilder 启用并发编译时,需要设置 Builder.SupportConcurrentCompilation 为真,并根据需要指定 Builder.NumCompileThreads。需要意识到 LLJIT 在启用并发编译机制时,会为安全并行克隆模块到独立的 LLVMContext。这可以保证模块数据结构在多个线程间不发生共享访问,但模块克隆本身代价巨大,会吞噬并发收益。换言之,粗暴启用并发并不总能带来线性加速,尤其当模块较大时,克隆开销会成为主要瓶颈。
性能案例与现实观察 以 csmith 生成的复杂自包含模块作为负载进行测试,可以清晰看到 TPDE 的优势。在没有优化且不回退到 LLVM 的理想条件下,TPDE 可以比默认 LLVM 后端在编译时间上实现显著加速,作者示例中曾观测到高达 20 倍的速度提升。在把 LLVM 优化等级调整为 -O0 后,这个速度提升仍然显著但会下降到一个较为合理的倍数,比如 12 倍左右。 然而多线程场景并不一定总是带来预期的加速。当 LLJIT 激活并发机制时,模块克隆和 ORC 的任务调度细节会影响整体延迟。具体问题包括 InitHelperTransformLayer 自动克隆模块、DynamicThreadPoolTaskDispatcher 在任务划分时为部分任务仍然创建新的线程、以及线程本地实例数量与任务数量的不匹配等。
实际测量中,作者发现启用 8 线程并行时,整体编译时间从 2200ms 降至 737ms,但深层次分析显示模块克隆与调度策略仍然制约进一步缩减时间。 工程实践建议 在考虑将 TPDE 集成到生产系统时,下面一些实践建议能帮助避免常见陷阱并提升工程鲁棒性。 谨慎选择是否使用 LLJITBuilder。如果想完全摆脱 LLVM 自带目标后端的依赖,需要手工构建 ORC 的组件,而不是使用 LLJITBuilder 的便捷工厂方法。LLJITBuilder 在内部会触发 TargetRegistry 相关初始化,导致你必须提供并初始化 LLVM 本身的后端,这在某些轻量化部署中并不理想。参考 tpde-lli 工具的实现可以看到如何通过手工组装 ORC Layer 来避免向外部暴露 LLVM 后端。
启用回退并记录失败样本。将 TPDE 作为主路径、LLVM 作为回退路径的策略可以最大化性能收益同时保证兼容性。对每次回退进行日志化,并保留失败的 IR 示例,用于之后增强 TPDE 覆盖或微调编译器前端。频繁回退的工作负载表明 TPDE 的覆盖不足,可能需要评估是否适合持续使用。 为并发编译做好内存与初始化成本控制。线程本地 TPDE 实例可显著减少每次编译的开销,但会带来更多的内存占用与初始化延迟。
理想方式是让每个工作线程在启动时初始化自己的 TPDE 实例,并复用该实例处理多次编译请求。与之配套,避免不必要的模块克隆,或者在允许的情况下,尝试在单线程内重用 Module 并行调度函数级别的编译任务。 深入理解 ORC 的调度器和 transform layer。LLJIT 的封装虽然易用,但把底层细节隐藏起来也会限制调优空间。对于对性能有严格要求的场景,建议查阅 ORC 源代码、理解 InitHelperTransformLayer、DynamicThreadPoolTaskDispatcher 等组件的行为,必要时实现自定义的任务调度器或 transform layer,以便更好地控制线程复用与任务划分。 实用的调试与测试方法 在集成与验证阶段,保持可重复的测试基线非常重要。
使用自包含的测试模块(如由 csmith 生成的 IR)可以模拟复杂负载。对比不同配置下的时间统计,包括单线程 TPDE、单线程 LLVM、并发 TPDE 与 TPDE+回退等多种组合,能帮助快速定位瓶颈。此外,通过日志提高可观察性,例如在 TPDE 编译失败时输出失败原因与触发函数名,可以评估 TPDE 的适配率。 在多线程测试中,监控内存使用、线程创建/销毁频率以及上下文切换,对判断是否存在线程调度或锁争用问题非常关键。必要时使用性能分析工具(如 perf、VTune 或系统自带的追踪工具)来检查热点和阻塞点。 面向未来的方向 TPDE 的上游化和与 ORC 的更紧密集成是值得期待的改进方向。
TPDE 作者和社区若能提供一个官方的 ORC layer,将显著降低集成成本并为更多项目所用。此外,改进动态任务调度器以避免过度的线程创建、减少模块克隆带来的开销,以及在 TPDE 中逐步扩大指令集覆盖范围,都会帮助推广 TPDE 在生产环境的可用性。 总结与取舍 将 TPDE 与 LLVM ORC 结合,能够为特定的即时编译场景带来显著的编译时延迟改善。关键在于理解它的设计边界,并通过回退机制和合理的并发策略来弥补覆盖不足。工程上需要在便捷性、依赖与性能之间做出权衡:LLJITBuilder 提供简单路径但附带 LLVM 初始化依赖,手工组装 ORC 则能实现更细粒度控制但开发成本更高。通过日志驱动的回退策略、线程本地编译器实例管理以及对 ORC 调度器的深入理解,工程团队可以把 TPDE 打造成一个既高效又可靠的 JIT 编译选项。
。