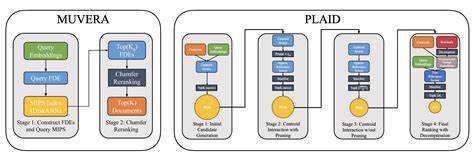
在当今数据驱动的时代,信息检索技术的发展至关重要。随着神经嵌入模型的广泛应用,检索系统已经从传统的关键词匹配演变为基于语义向量的深度匹配。尤其是多向量检索模型,如ColBERT,因其更加细致地捕捉文本中的多粒度信息,极大地提升了检索的相关性和准确性。然而,多向量模型在带来提升的同时,也引入了巨大的计算负担,导致检索效率难以满足大规模应用需求。针对这一挑战,Google Research推出了Muvera,一种通过固定维度编码(FDE)技术,将多向量检索转化为单向量最大内积搜索(MIPS)的创新算法,从而实现了准确性与高效性的完美平衡。 多向量检索的核心优势在于其细粒度的语义匹配能力。
不同于单向量模型将整个文本压缩为一个固定长度的向量,多向量模型生成多个向量,往往对应于文本中的各个词或片段,通过复杂的相似度度量(如Chamfer相似度)来捕捉查询与文档之间的细致对应关系。这种方法能够更好地反映文本中不同部分间的语义联系,显著提升了检索的召回率和精度。然而,Chamfer相似度的计算涉及非线性矩阵操作,需要逐一比较查询向量与文档向量集,造成计算成本的指数级增长,难以实现快速响应。 Muvera的出现,正是为了解决这一难题。它通过引入固定维度编码,将多向量集映射为单一向量,以此近似原始的Chamfer相似度。具体而言,Muvera构建了一种随机分区机制,将嵌入空间划分为多个区域,根据每个查询或文档向量所在的空间位置,将其投射到FDE的对应坐标上。
查询向量集合在同一区域内的向量对应坐标进行求和,而文档向量则采用了区域内向量的均值,这种设计巧妙地捕捉了Chamfer相似度中包含特征的非对称性。此外,FDE的生成过程是数据无关的,保证了算法在多样化的应用场景中的适应性和稳定性。 通过这一创新机制,Muvera成功将多向量复杂的匹配问题转化为单向量的最大内积搜索,利用目前高度优化的MIPS算法进行快速检索。检索结果经过初步筛选后,再通过准确的Chamfer相似度进行再排序,确保了检索的准确性不受影响,同时显著降低了计算时间和资源消耗。实验结果显示,Muvera在BEIR基准数据集上比先前最佳方法PLAID实现了近90%的延迟降低,且召回率提升约10%,在保证高召回的同时,候选文档数量减少了5至20倍,极大地提升了整体系统的响应速度和用户体验。 Muvera不仅实现了速度的质的飞跃,还具备出色的可扩展性和内存效率。
通过与产品量化技术相结合,Muvera的FDE能够实现高达32倍的压缩,且对检索性能的影响微乎其微。这意味着在面对海量数据时,Muvera能够以较低的内存占用维持高效的多向量检索能力,为大规模检索系统提供了坚实的支撑。 技术上,Muvera受到了概率树嵌入理论的启发,将几何算法中的随机划分思想巧妙地应用于内积空间的相似度近似。这一跨领域的创新实现了对复杂多向量结构的高效编码,并提供了严谨的理论保证,确保FDE能够以可控误差逼近Chamfer相似度。这种理论与实践的结合赋予Muvera极强的前瞻性,促使其在学术和工业界获得广泛关注。 Muvera的实际应用前景极其广阔。
诸如搜索引擎、推荐系统以及自然语言处理等领域,均面临着海量数据的快速检索需求。特别是在多模态数据融合和大型语言模型集成的背景下,多向量检索的重要性日益凸显。Muvera的效率提升将直接推动这些系统在响应速度和用户体验上的进步,使得更复杂、更精准的语义检索成为可能。 总结来看,Muvera为多向量信息检索领域开辟了一条新的高效路径。它通过固定维度编码有效简化了复杂的多向量相似度计算,不仅成功提升了检索准确度,还极大地降低了延迟和计算成本。Muvera的创新算法不仅在理论上具有坚实的支撑,也在实际应用中展现出卓越的性能和扩展潜力。
随着开源实现的发布,Muvera有望成为推动未来智能检索和深度语义理解的重要技术基石,为行业带来深远影响。未来,随着进一步的研究和优化,其应用范围将更加广泛,有望在更多场景中助力信息检索技术迈上新台阶。









