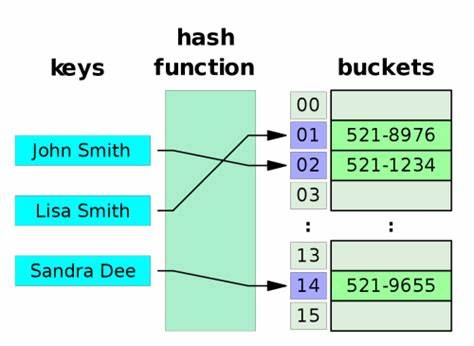
随着现代应用对海量数据处理能力的需求日益增长,数据库分区技术成为提升系统性能和扩展性的关键手段。在众多数据库系统中,PostgreSQL凭借其强大的功能和灵活的分区策略备受青睐。分区表通过划分数据,提高查询响应速度及维护便利性,而哈希分区则是其中常见且高效的分区策略之一。针对这种需求,pg_hash_func Ruby gem应运而生,提供了一种无需额外数据库查询即可精准计算PostgreSQL哈希分区索引的解决方案,极大提升了应用开发的便捷性和性能表现。 pg_hash_func是一款专门模拟PostgreSQL内部分区哈希函数的Ruby库。传统上,要确定某个整数键属于哪个分区,通常需要运行SQL查询调用数据库内置的哈希函数,从而获得分区索引。
该方法虽然准确,但频繁的数据库调用会增加系统开销,增加延迟,尤其是在分布式架构或者高并发环境下表现更为明显。pg_hash_func通过精准复制PostgreSQL源码中hashint8extended(针对bigint类型)和hashint4extended(针对integer及smallint类型)函数的算法逻辑,实现纯Ruby环境下本地计算分区索引,避免了频繁访问数据库的瓶颈。 该库特别针对整数类型设计,支持bigint、integer和smallint三种数据类型,满足绝大多数与数值分区相关的业务需求。它只能应用于PostgreSQL默认的哈希分区方式,不支持其他类如列表分区或范围分区,也无法处理文本、日期、浮点等非整数数据类型。这保证了算法实现的简洁与高效,并严格遵循PostgreSQL官方哈希策略的标准,实现兼容性同时确保精准对应每个键值的分区位置。 从技术实现角度来看,pg_hash_func严格还原源自PostgreSQL核心模块hashfunc.c中的算法细节,其中包含特定的种子值和混淆常量,用于对输入整数进行一系列位运算和移位操作,以生成均匀分布的哈希值。
随后结合分区数量,使用模运算确定最终的分区索引。开发者只需调用库提供的calculate_partition_index_bigint或calculate_partition_index_int4方法,传入键值与分区数,即可即时获得目标分区编号,省去了数据库层面的计算延迟。 使用pg_hash_func的典型场景包括需要前端或独立应用层预先判断数据走向的系统设计。例如,在分布式消息处理或缓存系统中,消息消费者无需先访问主数据库就能确定归属的分区位置,从而高效路由和存储数据。在进行批量写入前,也可以快速分配数据,实现负载均衡和分区并行处理。特别是当采用两级分区结构,例如先按用户ID(bigint)分区,再按业务类型(integer)分区时,pg_hash_func能够灵活调用对应算法,计算多层分区索引,提升系统架构的扩展性。
安装和使用同样简单便捷。用户只需在Gemfile中添加gem 'pg_hash_func',执行bundle install快速完成依赖安装,或通过gem install pg_hash_func独立安装。功能接口设计简洁,示例代码清晰,方便开发者根据实际业务参数调用。集合Ruby高效流畅的编码环境与PostgreSQL可靠分区策略,实现了最佳性能组合。 由于pg_hash_func专注于核心分区计算逻辑,保证了跨PostgreSQL版本的兼容性,目前支持从11到16版本,符合主流数据库升级节奏。此外,开源社区的积极维护和代码审查确保稳定性和安全性,为企业级应用提供坚实保障。
项目托管于GitHub,欢迎开发者参与反馈和贡献,推动功能不断完善和适配更多场景。 总结来看,pg_hash_func Ruby gem凭借其精准模拟PostgreSQL默认哈希分区算法的能力,为开发者和系统架构师提供了一种高效、可靠的本地分区索引计算工具。它不仅减少了数据库交互成本,提高了分区决策速度,还简化了代码逻辑,使数据分区管理更加灵活和透明。未来,随着分布式数据库和微服务架构的广泛应用,这类轻量级、无需依赖数据库查询的工具将会愈发重要,成为构建高性能数据驱动应用的基石。对于注重性能优化和系统弹性的团队和个人,深入掌握并应用pg_hash_func无疑是提升PostgreSQL数据库分区策略实践水平的重要一步。