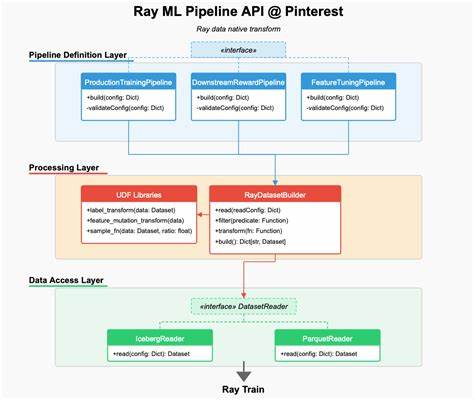
在现代互联网企业中,机器学习技术已经成为推动业务创新和提升用户体验的核心驱动力。作为全球领先的视觉发现引擎,Pinterest拥有数百亿的创意数据,背靠强大的数据资源,Pinterest的工程师团队对机器学习基础设施提出了极高的要求。传统的机器学习流程中,复杂的特征开发、冗长的数据预处理以及高成本的计算资源消耗成为了制约快速迭代和大规模扩展的关键瓶颈。为了打破这些限制,Pinterest引入并深度定制了Ray开源计算框架,从训练和推理环节出发,逐步扩展到整个机器学习数据流水线,打造了面向下一代机器学习需求的基础设施体系。 Pinterest的机器学习团队通过Ray构建了由原数据处理、特征变换、数据连接到模型训练和部署的端到端流水线。传统基于Spark的特征开发流程不仅耗时长、资源占用大,而且功能调优复杂,成为工程师创新尝试的障碍。
此外,采样实验和标签重计算流程的高延迟也影响了新算法的快速验证。Ray的引入带来了根本性的改变,尤其是在数据转换API的定制、Iceberg数据湖的高效桶式连接以及数据持久化机制上的创新,使得数据处理变得更加简洁高效,极大缩短了模型迭代周期。 Pinterest开发了专门的Ray Data本地流水线API,实现特征开发、采样及标签变换的即时处理,摒弃了对离线批处理的依赖。API设计高度抽象,确保代码和数据转换工作能够无缝迁移到不同的数据框架之上,例如Spark或深度学习库PyTorch。这种架构的好处在于促进了跨团队协作,简化了维护成本,并对未来功能扩展形成良好支撑。 数据连接方面,Pinterest基于Iceberg表格式设计了创新的桶式连接机制,有效解决了多数据源特征合并的难题。
传统方法需提前计算大型数据表并存储,造成存储浪费和计算延迟。通过动态读取分区并行执行连接操作,Ray能够以极低的延迟实现精准匹配,连接策略灵活支持多种场景,且通过自研的文件解析与分区映射系统应对命名不一致的挑战。这不仅提升了数据处理速度,还大幅减少了数据搬移,降低了存储和网络开销。 持久化方面,Pinterest利用Ray集成了Iceberg的写入机制,实现了特征数据的缓存与复用。在实际训练过程中,经过持久化的特征无需每次都重新计算,模型调优和超参数测试效率显著提升。更重要的是,该机制支持特征从研发到上线的平滑过渡,让生产环境的数据生成与特征服务保持一致,保障了模型性能的稳定与可持续提升。
为满足亿级样本和海量特征的处理需求,Pinterest持续对Ray Data底层进行性能优化。通过消除不必要的内存拷贝、优化用户自定义函数的执行效率、利用Numba进行即时编译,团队实现了2至3倍的处理速度提升。优化措施聚焦在减少数据切片带来的开销,强化UDF合并与高效转换等关键步骤,最终使得训练流水线达到了接近硬件理论峰值的处理效率。 Pinterest由此打造的基于Ray的全流程机器学习基础设施,彻底变革了传统研发模式。流水线一体化减少了从特征设计、采样、标签生成到训练部署的各环节之间的摩擦,实验时长缩短了10倍以上,同时显著压缩了计算成本。研发团队能够更专注于算法创新及用户价值挖掘,大幅提升了组织的敏捷性和生产力。
展望未来,Pinterest计划进一步深耕Ray生态,提升数据处理与缓存机制的深度和复杂度,并探索将大规模语言模型整合入推荐系统的新场景。通过将Ray的强大算力十分快速响应于用户行为序列分析和生成式模型实验,Pinterest期望在个性化推荐和用户体验创新上实现全新飞跃。 Pinterest通过将Ray从传统训练框架扩展至机器学习全栈,建立了业界领先的高效、灵活且可扩展的基础设施体系。这不仅加速了模型的研发迭代,降低了工程及运营成本,也为其他大型互联网企业提供了宝贵的经验与范例。未来,随着机器学习应用的多样化与复杂性增加,Ray所代表的分布式计算框架将在行业中扮演愈发关键的角色,引领机器学习基础设施迈向更广阔的可能。