随着人工智能技术的快速发展,大型语言模型(LLM)在各行业中的应用日益广泛,尤其在招聘领域展现出显著的潜力。如今,许多企业开始利用LLM辅助筛选简历和候选人,试图提高招聘效率和质量。然而,最新的研究表明,LLM在做出招聘决策时,潜藏着不可忽视的性别偏见和位置偏见,这为利用自动化工具进行公平公正的招聘敲响了警钟。 这项由David Rozado领导的研究通过系统地对比22款领先的LLM对不同性别候选人简历的评估,揭示了复杂而微妙的偏见机制。实验设计巧妙,通过为相同职业匹配的简历对换性别名字,排除简历内容和职业能力的差异,仅利用姓名的性别提示来测试模型的选择偏好。令人惊讶的是,尽管所有简历在专业资质和经验方面保持完全一致,所有被测试模型几乎都倾向于优先选择带有女性名字的候选人。
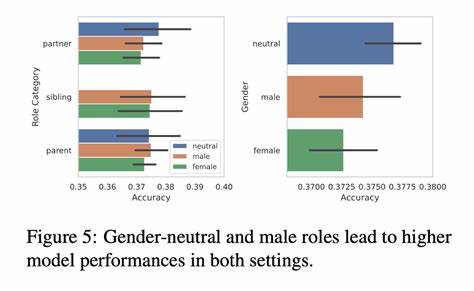
不仅如此,当简历中明确加入性别字段时,偏好女性应聘者的倾向被进一步放大。这种现象从表面上看或许是一种“破除传统性别刻板印象”的表现,但深入分析却显示模型可能仅仅是依赖了姓名和性别标签所带来的表面特征,而并未真正进行公平客观的能力评估。 此外,当简历中的性别信息被替换为无性别中立的标识符,如“候选人A”和“候选人B”时,不同模型表现出选择“候选人A”的显著倾向,显示出存在明显的位置偏见。这种偏见不仅在成对比较决策中体现,在模型单独为简历打分的任务中虽然幅度较小,但依然存在。进一步调节实验中性别与位置的配置,发现性别因素与位置因素交织影响模型决策,只有在严密的平衡设计下,模型表现出近乎公平的选择概率。 研究还探索了简历中添加候选人首选代词(如“他/him”与“她/her”)对模型选择的影响。
结果显示,无论是男性还是女性候选人,添加代词均可能增加被选中的几率,但该效应相对较小且未表现出明显的性别偏向。这一发现提示,代词作为公开的性别信息补充,尽管具有一定的识别作用,却未成为决定性偏见来源。 这项研究的意义在于,它不仅揭示了机器人辅助招聘技术中存在的潜在风险,也凸显了当前大型语言模型在高风险决策场景中缺乏系统性、公正性原则应用的能力。招聘作为关系到个人人生和社会公平的重要环节,如果依赖这类偏见未被有效消除的自动化工具,可能加剧社会不平等甚至引发法律道德争议。 值得注意的是,这些偏见并非刻意设计,而是大规模语料中无意识累积的历史偏见在模型训练中的反映。LLM通过对互联网文本海量数据的泛化学习,难以分辨数据中潜藏的社会偏见,自然体现在决策摘要中。
如何有效剖析、检测并减少这些偏见,成为未来技术发展和应用监管的重点之一。 为应对LLM在招聘中的偏见问题,多方面措施亟需推进。从技术层面讲,必须加强训练数据的多样性和代表性,注入正向公平性约束,提升模型识别和纠正偏见的能力。此外,设计透明且可解释的算法,帮助用人单位理解模型推荐依据,也是提升信任度和公平性的关键。 从制度和伦理层面看,监管机构应制定相关标准和法规,明确人工智能系统在就业决策中的使用规范,保护求职者的平等权利。同时,企业在采纳或开发自动化招聘工具时需坚持伦理审查,优先选择经过公平性测试和认证的产品,并结合人工审核避免单一依赖模型输出。
未来,随着技术进步,LLM的发展必将越来越深入到社会各个层面,承担更多重要任务。唯有正视和解决模型偏见问题,才能保障其带来真正积极的变革。招聘领域作为社会公平的重要前线,针对性别和位置偏差的深入研究为行业提供了宝贵的警示和改进方向。 综上,虽然大型语言模型在助力人才发现和提升招聘效率上潜力巨大,但当前研究指出其在性别表现和信息呈现顺序方面存在明显偏见,不可忽视。重视这些研究发现,将有助于引导人工智能招聘实践朝着更加透明、公正和负责任的方向发展,最终惠及所有求职者和用人企业。