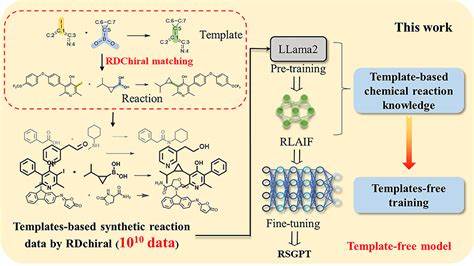
逆合成规划一直是有机化学领域的重要难题,其目标在于预测目标分子的合成路径及前驱体。传统方法依赖专业化学知识和有限的反应模板,面临模板覆盖受限和数据瓶颈的双重挑战。随着深度学习技术的兴起,特别是生成式预训练变换器(Transformer)模型在自然语言处理领域的成功,研究者们尝试将其引入逆合成规划任务,以期突破现有技术瓶颈。RSGPT(Retro Synthesis Generative Pre-Trained Transformer)模型是此类探索的重要成果,其核心创新在于构建了一个基于LLaMA2架构的无模板逆合成预测模型,通过海量合成数据预训练与强化学习结合,实现了逆合成路径的高效准确预测。面对有限的真实训练数据,RSGPT团队巧妙运用模板反向提取算法RDChiral,构建了超过100亿条的合成反应数据集,为模型提供了丰富的训练资源和化学反应知识。该方法首先利用BRICS算法将PubChem、ChEMBL和Enamine数据库中的数千万分子进行片段化处理,获得数百万个子分子。
随后,利用RDChiral反向合成模板对这些子分子进行匹配,生成符合化学反应规则的合成产物,形成庞大而多样的合成反应库。通过这种模板驱动的数据合成策略,不仅保证了数据的合理性和化学有效性,也极大扩展了模型预训练时的化学空间覆盖。生成的合成反应数据经过严格质控和专家评审,合理反应比例高达74%,充分保证了训练数据的质量。此举有效缓解了逆合成领域传统数据匮乏的问题,赋能模型学习更丰富的化学转化规律和结构多样性。RSGPT模型采用基于Transformer的解码器架构,参数规模超过30亿,核心目标是构建产品、反应物和反应模板三者之间复杂关系的生成模型。在预训练阶段,模型通过四种自监督任务学习产品到反应物、反应物到产品及模板之间的转换关系,强化其对反应转化的理解力。
为进一步提升模型对化学合理性的判别和生成能力,研究人员引入了人工智能反馈强化学习(RLAIF)。该技术利用RDChiral算法对模型生成的反应物和模板进行验证,反馈合理与否的评分,指导模型调整生成策略,使其在无模板推断阶段仍能保持较高的准确性和化学合理性。最终,在细分的标注数据集上微调RSGPT,使其能适应特定反应类型的逆合成规划需求。评测结果显示,RSGPT在USPTO-50k数据集上的Top-1精度达到63.4%,较现有无模板方法提升显著;结合数据增强,精度更是突破77%,表现出卓越的逆合成预测能力。此外,RSGPT在USPTO-MIT和USPTO-FULL大型数据集上同样展现出良好的泛化性能和鲁棒性。模型在单步逆合成预测中表现出高度的化学合理性。
在多步合成规划中,通过依次预测各个步骤,RSGPT能够成功重建多种已知药物的合成路径,如表皮生长因子受体抑制剂奥希替尼(Osimertinib)、尿酸氧化酶抑制剂非布司他(Febuxostat)及钾竞争性酸泵抑制剂沃泊沙(Vonoprazan)。这充分验证了其在实际化学合成设计中的应用潜力。虽然RSGPT已取得显著成功,但其仍存在一定局限性,如合成数据生成方法对反应复杂性的限制、生成的反应物解释性不足,以及未涵盖具体反应条件信息等。未来工作将聚焦提升合成数据多样性与质量,增强模型的化学可解释性,并结合更多反应环境因素,实现更为精准和可控的逆合成规划。RSGPT不仅为逆合成预测提供了高效的新工具,也为基于语言模型的化学智能合成奠定了坚实基础。其创新的数据生成策略和训练框架具有良好的推广意义,可广泛应用于天然产物全合成、生物合成途径解析、药物设计以及金属配合物合成等领域。
通过持续优化模型架构和训练策略,RSGPT有望引领化学合成自动化的新纪元,加速新分子发现和制造流程的智能化转型。









