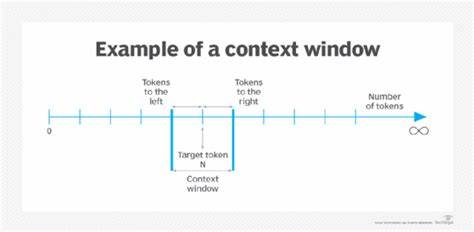
随着人工智能技术的不断进步,能够进行复杂推理和决策的智能体逐渐成为研究和应用的热点。推理智能体在医疗诊断、法律分析、商业决策等诸多领域展现出巨大的潜力,而这些能力的实现离不开模型对输入上下文的深度理解和高效利用。然而,当涉及长上下文输入时,推理智能体普遍遭遇一种被称为“上下文窗口饱和”的现象,这一问题不仅妨碍了模型的性能提升,也对实际应用造成严重影响。理解上下文窗口饱和的机理及其表现,对提升智能体的推理能力和部署效果至关重要。上下文窗口饱和指的是推理模型在处理包含大量信息的长输入时,随着更多信息的加入,模型的性能不能持续提升,反而出现错误增加、思考混乱和推理效率下降的现象。简单来说,当智能体接收到大量信息超出其处理能力的极限时,模型难以有效区分关键信息与噪声,导致认知负荷过重,推理路径变得模糊不清。
模型可能陷入“过度思考”,产生无限循环的思维过程,甚至输出与问题无关或者错误的答案。与之相对的是上下文窗口的技术限制。当前主流的语言模型多基于Transformer架构,其计算资源和内存消耗与输入长度平方成正比。尽管市场上已有支持十几万甚至几十万令牌长度上下文的模型,如GPT-4.5和Claude 3,但硬件负担极大,且长上下文的实际推理收益有限。实际上,最新研究表明,单纯扩大上下文长度并不显著提升模型性能。原因在于,模型难以保持对所有输入信息的均衡关注,导致中间部分的关键信息被忽略,也称为“信息遗失在中间”。
此外,输入的冗余和模糊信息增加了理解难度,使推理逻辑发生偏差。实际应用场景中,如处理复杂的法律文书、金融报告或客户反馈,文本中往往包含大量重复、矛盾和模糊信息。模型在面对这种高度复杂的长文本时,小小的误差累积便会导致整体推理失真,降低回答准确率。上下文窗口饱和带来的另一个核心问题是“针叶藏于干草堆”效应,即关键信息像针一样被埋藏在大量无关内容中。尽管模型理论上有足够的上下文容量,但其注意力机制难以在海量信息中精准提取重要内容,尤其是位于中间区域的信息经常被忽视。这一漏洞显著制约了超长上下文模型的应用效果。
面对上下文窗口饱和的挑战,学界和工业界提出了多种切实有效的解决方案。首先,优化输入提示设计是增强模型性能的关键环节。通过对传入内容进行精简和重构,突出信息的核心要素,使模型能够专注于高信号数据,避免因低效内容浪费计算资源。其次,文本块切分技术(Chunking)被广泛采用,即将长文本拆分成语义一致的小段落,有助于模型逐块理解与推理,减少整体记忆负担。这种方式可以搭配多次检索和输出融合策略,提升信息覆盖率和准确性。为了缓解上下文内部信息的相互干扰,研究者开发了多种去噪和信息整合机制。
例如,使用代表性样本(Medoid Voting)代替全量信息输入,基于抽样结果获得更稳健的输出。还有引入滑动窗口注意力机制的方法,如Longformer模型,专注于局部内容的相关性,提高了长序列处理的效率并有效缓解了资源消耗瓶颈。在记忆管理方面,一些创新模型采用增量式语义相关信息流(PI-LLM),通过逐步输入关键-值对减少上下文信息的冗余,提升实时推理的连贯性和准确性。同时,人们引入“过度思考检测”机制,帮助模型识别并中断无意义的推理循环,避免陷入对准确答案的反复怀疑,节省资源并改善响应时间。针对推理方向的引导技术也取得明显进展,通过激活引导(Activation Steering)调控内部神经元的活跃程度,调整模型推理路径,使其更聚焦于合理且高效的思考链条,从而提升整体推理质量。反观推理智能体设计的整体架构,开发者应注重上下文的工程学设计。
合理管理会话缓存、短期记忆缓冲区及思维日志,避免简单将所有信息堆砌于单一上下文窗口。利用结构化信息存储与检索机制,动态调整输入内容,确保模型获取最相关且及时的信息。此外,结合检索式增强模型和层次化推理框架,能够有效拓展模型的知识覆盖和通用能力,且不必盲目依赖超长上下文。尽管现实中仍存许多挑战,但未来推理智能体的发展方向已然清晰。突破上下文窗口饱和的瓶颈,提升对长文本的处理能力,依赖的不仅是扩容上下文的硬件资源,而是深度理解信息组织方式和改进推理机制。强化模型的注意力分配策略、结合外部知识库和持续学习能力,将成为下一代推理智能体实现人类水平思维的关键。
此外,跨模态信息融合、多模态推理与记忆协同也为解决上下文管理提供了广阔前景。总而言之,动力强劲的研究和技术创新正引领推理智能体迈向更智能、高效的未来。在实际应用中,开发者需科学规划上下文结构,注重语义清晰度和重点突出,合理运用分块、检索与激活指导技术。唯有如此,才能真正驱动智能体发挥其推理潜能,助力解决复杂任务,推动人工智能价值的深度释放。