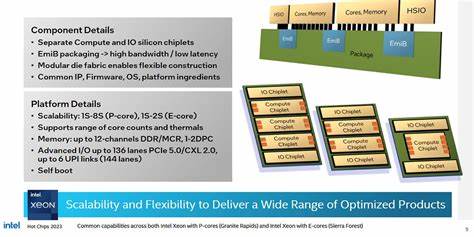
引言 近年来服务器处理器市场竞争白热化,Intel 在 Xeon 6 平台上采用了更积极的 chiplet 设计以提升可扩展性和吞吐能力。本文从内存子系统角度出发,结合在 AWS r8i 实例(Xeon 6 6985P-C)上的实测数据,深入解析缓存层次、NUMA 拆分、跨片互连与实际延迟/带宽表现,并讨论面向不同负载的调优策略与实务建议。 总体架构与关键硬件特征 Xeon 6 6985P-C 核心为 Redwood Cove 微架构,单颗芯片实际启用 96 个内核,每核配备 2MB L2。Redwood Cove 在指令缓存与向量单元上具备改进,并在服务器产品线上支持 AVX-512 与 AMX。芯片采用多片片(chiplet)设计,最多可包含三个计算 die 与两个 IO die,计算 die 仅包含核心与 DRAM 控制器,IO 相关功能与低速加速器则迁移到 IO die。 芯片内部采用 mesh 互连以维持逻辑上的单片感受。
每个核心对应一个 CHA(Caching/Home Agent),CHA 内含 L3 缓存切片与 snoop 过滤器。6985P-C 存在约 120 个 CHA,合计约 480MB 的 L3 缓存。计算 die 边缘布置 MDF(Modular Data Fabric)网点并跨 die 使用 Intel 的 EMIB 物理互连,官方未公开完整拓扑,但实测揭示了跨片访问的延迟/带宽特征。 内存控制器与 NUMA 拆分 Xeon 6 在计算 die 的短边处放置内存控制器,最大配置为 12 个内存控制器(每个计算 die 四个)。AWS 在 r8i 节点上配置了每插槽 1.5TB 的 Micron DDR5-7200,并默认启用 SNC3 模式。SNC(Sub-NUMA Clustering)将芯片划分为三个 NUMA 节点,每个节点由本地的 L3 切片和内存控制器支撑,这样的划分有助于保持本地访问亲和性以降低延迟。
缓存与内存延迟特征 Xeon 6 的 L1D 与 L2 在周期数上与移动端的同代核类似,但因整体频率偏低在实际纳秒延迟上表现较高。测得的 L3 命中延迟大致在 33ns 左右(约 130 个时钟周期),比前一代 Emerald Rapids 稍有回退。尽管 L3 容量大(部分 tile 可提供约 160MB 的局部 L3 访问池),但较高的基线延迟使得 L3 命中在某些延迟敏感场景下变成瓶颈。 与之对比,AMD Zen 5(代号 Turin)在内存延迟与 L3 性能上展现不同的折衷。AMD 采用更小、更高性能的 L3 实例(每 8 核共享 32MB),单实例响应更快但整体 L3 空间分布更碎片化。实测中 AMD 平台总体内存延迟约 125.6ns,在某些配置下仍优于 Xeon 6 的跨 NUMA 或跨片访问延迟。
跨片互连与远程访问代价 Xeon 6 采用一致性哈希将物理地址映射到对应的 CHA,从而使每个 NUMA 节点的地址空间主要在其所属计算 die 的 L3 切片上被缓存。这样远程 NUMA 访问不会被其他 die 的 L3 缓存广泛服务,访问位于相邻 die 的 L3 会增加大约 24ns 的开销,跨越两个 die 的 L3 命中延迟接近 80ns。远程 DRAM 访问同样显著更慢,跨越一个 die 边界大致增加 26ns,跨越两个边界则进一步上升。 在高并发负载下,延迟随带宽使用率上升而增加,直至到达带宽饱和区间后出现陡峭上升。Xeon 6 在设计上能够在相当高的并发下保持延迟相对可控,但跨片访问带来的固定惩罚仍然存在,尤其对对延迟敏感或非 NUMA 亲和的应用影响明显。 带宽表现与吞吐能力 Xeon 6 在每核缓存带宽与芯片级带宽上做了明显放大。
单核 L3 读取带宽约为 30GB/s,L3 的读写模式(例如读修改写)能显著提高可测带宽,类似于 Zen 系列中因 victim cache 或写回机制所带来的带宽翻倍现象。单核从 DRAM 的可观带宽略低于 20GB/s,较 Zen 5 小幅落后,但通过更大的 L3 缓存,Xeon 6 能将更多工作集留在更接近核心的层级,从而减轻对 DRAM 的直接依赖。 在整芯片测试中,当各线程访问本地 NUMA 节点并保持数据亲和时,测得的 DRAM 总带宽约为 691.6GB/s,显著优于先前一代 Emerald Rapids 的约 323.5GB/s,也超出我手上测试的 AMD EPYC 9355P 的约 479GB/s(该 AMD 系统运行 DDR5-5200)。更重要的是,Xeon 6 的高核心数和快速 L1/L2 缓存使其在本地化良好的吞吐型负载下能展现极高的整体带宽。 跨片带宽方面,Xeon 6 的跨 die 读带宽接近 500GB/s,对于特定的访问模式并尊重芯片的"连章式"拓扑(例:节点 0 访问节点 1,节点 1 访问节点 2),在读修改写模式下甚至能突破 800GB/s。这展示了 Intel 在 mesh 与 EMIB 互连带宽上的工程实力,但这种高带宽通常伴随不可忽视的延迟惩罚,因此在架构层面仍有权衡。
缓存一致性与核间通信延迟 核间缓存一致性操作(例如在两核间 bounce 数据)在 Xeon 6 上表现延续了 Intel 以往的设计特征。位于同一计算 die 内的两核之间的往返延迟大约在 50-80ns,而跨 die 的一致性转移仅略有增加。最坏情况下,如果两核间转移需要经过最远的 CHA,延迟可达 100-120ns,但总体仍优于部分 AMD Server 平台在跨 CCX/CCDs 场景下的 150-180ns 区间。 这意味着对于需要频繁互相通信的线程或共享内存协议,Xeon 6 在打破片内边界后仍能维持相对较好的交互延迟,但最佳实践依然是尽量将相关线程与数据约束在同一 NUMA 节点内。 在云端使用的观察与调优建议 在 AWS r8i 等托管实例上运行 Xeon 6 时,SNC3 的默认配置对大多数云场景有利。SNC3 将芯片划分为三个较小的 NUMA 域,提升了本地 DRAM 访问与 L3 命中的概率,从而改善延迟敏感型负载的表现。
不过对于需最大化带宽且对延迟不敏感的吞吐型任务,统一(包内或系统层面)内存条纹化模式也可能带来更均衡的带宽分配。 对于系统管理员与开发者,务必采用 NUMA-aware 的进程/线程绑定策略,使用 numactl、taskset 或容器 runtime 的 cpu/memory pinning 特性将工作负载和其内存分配绑定到同一 NUMA 节点。对需要低延迟的服务,优先使用本地分配、关闭透明大页(在某些场景中)或启用合适页框预取策略可以降低平均延迟。对大内存带宽负载,启用并发内存访问、合理分配读写模式,并使用性能分析工具(例如 perf、numastat、pcm)来定位跨片访问热点,是获得稳定吞吐的关键。 此外,考虑到 L3 容量巨大,应用层可以通过优化数据布局与缓存友好算法来提升命中率,减少对远程 DRAM 的依赖。对于 JVM、数据库或大数据框架,调整堆/页分配策略以及内存分区可显著改善性能。
对比与工程取舍 Intel 与 AMD 在 server 级别采用了不同的系统级设计理念。Intel 倾向于保持逻辑上的单片视图,通过强大的 mesh 与一致性架构让更多代理共享更大的 L3 池,从而在某些工作负载下简化资源管理与编程模型。但这也要求高带宽、低延迟的跨片互连来弥补长物理距离带来的惩罚。AMD 则选择分层互连,块级内提供高性能低延迟的局部 L3,再借 Infinity Fabric 处理更慢的跨块通信,从而在延迟均衡上有不同优势。 在实际对比中,Xeon 6 凭借更多的内存控制器、更高频率的 DDR5 及更大的 chip-level L3,在带宽密集型负载上占优。但在纯延迟或某些单线程优化场景下,较低的 L3 基线延迟与更紧凑的 L3 设计仍可能让对手胜出。
是否要维持逻辑单片的复杂度,取决于应用生态对统一资源池的需求和可接受的跨片延迟。 面向未来的考量 Intel 已公布更先进的 Lion Cove 内核,旨在与 Zen 5 代核直接竞争。系统层面的演进仍将围绕如何在提升核心数与保持跨片延迟之间取得平衡。若未来在每个计算 die 内提升单个 die 的核心密度并保持高效的本地缓存策略,Intel 能更好地兼顾扩展性和延迟控制。反之,若继续扩展 mesh 规模而不强化跨片低延迟能力,则在某些负载上可能遭遇边际回报递减。 总结与建议 Xeon 6 在内存子系统上采用了明显倾向于带宽与容量的设计。
其优势在于大量内存控制器、高速 DDR5 支持与巨大的芯片级 L3,使其在吞吐型工作负载中表现卓越。缺点在于 L3 与远程 DRAM 的基线延迟较高,跨片访问带来的成本依然明显,因此在延迟敏感应用部署时需要谨慎规划 NUMA 亲和策略。 在云端部署方面,建议优先利用 SNC3 的本地化优势,为延迟关键任务绑定到本地 NUMA 节点,针对内存带宽密集型任务则可考虑更宽松的内存条纹化策略。应用开发者应关注数据布局、缓存友好算法与 NUMA-aware 调度,以充分发挥 Xeon 6 的带宽潜力。 总体而言,Xeon 6 展示了 Intel 在高带宽互连与大缓存设计上的能力,但系统级性能仍然依赖于软件与配置的配合。理解其内存子系统的细节与权衡点,对于在云端或裸金属环境中实现稳定、可预测的高性能至关重要。
未来核心微架构与互连技术的演进将继续决定大规模 chiplet 设计在实际生产环境中的价值。 。