在当今数据驱动的商业环境中,数据分析师的角色愈加重要。作为一名高级数据分析师求职者,能够用先进的分析方法解决实际业务问题,无疑能为你的职业生涯加分。本文将介绍作者在一场高级数据分析师面试中,如何运用市场篮子分析(又称关联规则挖掘)完成客户流失预测任务,以及这一过程中的经验教训和关键技巧。 市场篮子分析起源于零售行业,是一种发现用户购买行为中物品搭配规律的经典技术。简而言之,它通过分析大量顾客的购物“篮子”,揭示哪些商品经常被一起购买。近年来,这种方法的应用已远远超出传统零售,它对用户特征进行“配对”,例如哪些特征组合更可能导致客户流失,同样适用在客户保留和营销领域。
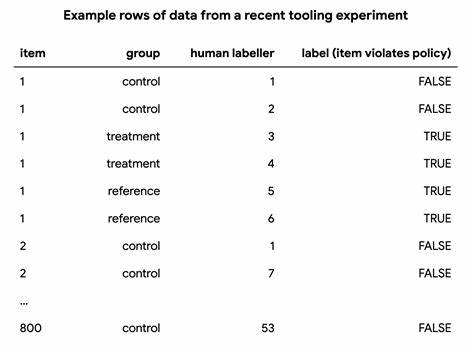
在面试的任务中,作者被要求分析一个科学出版平台的客户数据,识别哪些账户最有可能取消订阅。该任务涵盖了客户生命周期多个切面,包括客户所属地区、订阅类型、活跃度指标(如使用频次)、用户数量以及客户满意度评分(NPS)等多个维度。通过深入挖掘这些数据,希望提出切实可行的业务建议,帮助企业减少流失,增加收入。 首先是数据预处理阶段。要进行市场篮子分析,数据必须是二元的,即每个属性必须能够用“是”或“否”(True/False)来表示。现实中数据大多复杂多样,比如客户的收入、账户年龄等都是连续变量,难以直接用于该方法。
作者利用了Python数据处理库pandas中的qcut函数,将连续变量按分位点分箱成多个类别,将数值型数据转换为具备明确类别的信息,如“低”、“中”、“高”及“缺失”等。这一步骤极大地减少了特征维度,避免了过多类别导致计算资源消耗爆炸,提升模型效率。 接下来是针对类别数据的One-Hot编码。它将每个类别拆分为独立的二元特征列,使得每条记录可以对应一行多个True/False值。比如对“账户所在国家”字段进行一热编码,一条记录中“国家-德国”可能为True,“国家-美国”则为False。同时,作者通过删除部分本身直接体现流失状态的列,防止了模型“偷看答案”,从而保证关联规则挖掘的真实性和有效性。
在选择技术工具上,作者最初尝试了pycaret这个友好的机器学习库,这本应简化整体流程,但遭遇版本不兼容和依赖问题,最终转向更为成熟的mlxtend库。虽然mlxtend使用门槛略高,但凭借其强大且文档丰富的功能,作者成功挖掘出了多条具商业价值的关联规则。 关联规则的评估主要依据三个指标:支持度(Support)、置信度(Confidence)以及提升度(Lift)。支持度反映规则覆盖用户的比例,置信度表明条件发生时联合事件的概率,提升度则衡量事件发生概率相比于随机的倍数。为了保证结果的质量,作者反复调整这些阈值,减少冗余或无意义规则,同时保持关键洞见不缺失。 经过反复试验,作者发现一些关键规律,例如老账户(2012年注册)、客户用户数量少于4人、并且缺失满意度评分的客户,流失风险是正常客户的三倍以上。
此类洞察不仅有助于精准识别风险客户群,还指导了后续针对性服务和客户关怀策略的制定。 此外,作者强调单纯得出模型结论远远不够,向业务高层汇报时需要构建完整的数据故事。通过对比活跃与流失客户的价值贡献、用户数量与流失率的关系、账户年龄与收入的变化趋势,最终汇聚成简洁有力的演示文档。文档中不仅明确指出问题大小,还能合理预测防止流失带来的潜在收益,增强说服力。 整个分析流程经历了诸多挑战,特别是在数据转换和代码调试阶段,作者毫无保留地分享了碰到的技术难题与解决方案。这种真实的项目复盘对于数据分析师群体极具参考意义,展示了数据科学项目中的“冰山”部分:表面成果背后的大量准备和尝试。
这次面试案例还告诉我们,技术技能只是通往岗位的入场券,如何将数据洞察用通俗易懂的语言讲给非技术背景的业务人员听,是成为优秀数据分析师的关键。在对结果的解读中,通过讲述客户的背景、行为特征及其对营收的影响,让管理层能够清晰理解并采纳建议。 值得一提的是,尽管作者最终拒绝了该岗位,但此次市场篮子分析和相关演示对赢得面试官认可起到了决定性作用,彰显了数据分析的实战价值。面对当前求职市场,掌握并能熟练运用此类预测分析方法,会极大拓宽专业的职业视野和竞争优势。 总结来看,市场篮子分析作为机器学习中经典且高效的一种关联规则挖掘方法,不仅适合零售领域,也能够成功应用于客户流失和用户行为分析。在大数据时代,数据科学家的任务不仅是挖掘出规律,更要赋予洞察明确的商业价值。
如果你正准备数据分析类面试或者寻求优化业务流程的解决方案,不妨尝试从市场篮子分析入手,掌握数据预处理、精细调参及讲故事的技巧。相信你也能在数据的世界中,发掘出未来的机会与可能。