在人类评分成为许多科学研究和商业应用基础的时代,准确理解并衡量这些评分的质量显得尤为重要。人类评分所面临的核心挑战之一即是主观判断与评分结果之间的差异,如何判定评分是否既具有一致性又测量了真实想要评估的内容,是数据科学领域亟需解决的问题。有效性和信度作为评价测量工具质量的两大基石,为我们在这方面提供了理论支持和实践指南。 有效性,顾名思义,是指测量工具是否真正测量了预期想要测量的属性。信度则关注评分的稳定性与一致性,即在相同条件下重复测量能否产生相似结果。人类评分的有效性和信度互为依托,信度为最高有效性设定了上限,而未达到信度的测量则无法保证其有效性。
为了更好地评估这些评分,人们开发了多种方法,从经典的科恩卡帕(Cohen's Kappa)到近年来提出的跨复现信度(cross-replication reliability,简称xRR)框架。 科恩卡帕是评估两名评分者之间一致性的标准工具,它考虑到了评分者偶然达成一致的概率,该指标从1940年代起被广泛应用于心理学、医学等领域。科恩卡帕通过比较观察到的总体一致率和预期偶然一致率,从而得出一个更为准确的评分一致性指标,其值介于-1到1之间,越接近1说明评分者间越一致。然而,卡帕系数也存在一些限制,比如难以处理多于两人的评分情况和类别严重不平衡的问题。 为了突破这一限制,研究者们提出了多种扩展版本,如克瑞本多夫α(Krippendorff's Alpha)等,能够处理多评分者、多类别以及缺失数据的情形。除了非参数方法,统计学家还利用混合效应模型通过方差成分分解,计算出类内相关系数(intraclass correlation coefficient,简称ICC)来量化连续型评分数据的信度。
ICC反映了同一物体在不同评分者之间评分的一致性,更高的ICC值代表评分的稳定且有代表性。 然而,以上多数方法集中于单个评分组的内在一致性,并未完全解答“评分到底是不是有效的”的难题。尤其在面对主观性强、无明确“金标准”的评分任务时,单纯的信度指标可能导致误判。例如,一群评分者可能一致地给出错误的标签。为了更全面把握评分的有效性,跨复现信度(xRR)被提出,该方法通过比较不同评分群体之间的标签一致性,尤其是普通评分者与专家评分者之间的对比,揭示评分的真实性和准确性。 xRR的核心思想在于利用多个独立的评分池进行验证,评测其间的一致程度。
若两个评分池在同一批样本上的评分吻合度高,则增强了评分的客观性,即“可间主观性”,从而提高了测量的有效性。具体计算时,xRR采用与卡帕类似的结构,定义观察到的组间不一致和预期不一致,运用分子分母比值调整偶然一致影响。该方法适用于多种数据类型,包括二元分类、连续变量等,灵活性和解释力都较强。 更进一步,研究人员开发了规范化的xRR指标,又称标准化跨复现信度,其通过将xRR值除以各评分池的内部信度平方根的乘积,能够估算评分结果汇总后的相关性,这一方法尤其适合用于评估汇总后评分的有效性,确保了对评分系统整体表现的更精准评判。 为了更科学地解析数据,研究还结合了参数模型和非参数模型。参数模型如贝叶斯混合效应模型能充分利用数据结构,考虑评分者偏差和项目特异性差异,帮助刻画潜在真实评分分布及不确定性,通过模型化方差成分直接估算信度和有效性指标。
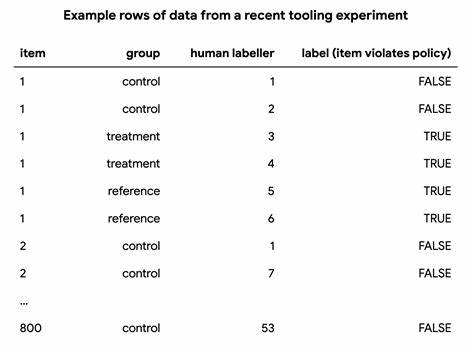
此外,参数化方法亦提供了置信区间等统计推断,能够辅助决策者判断测量结果的可靠范围。 测量有效性和信度的方法不仅理论意义重大,更对实际场景产生深远影响。以谷歌政策执行数据标注为例,针对广告内容是否违反政策的人工评分,通过设置对比组和实验组,以及专家参考组,运用上述指标系统评估不同标注工具的作用。尽管控制组评分在信度指标上表现突出,但xRR揭示其实标签更偏离专家判断,显示出较低的有效性。相反,实验组标注工具虽略微降低了信度,却显著提高了与专家评分的一致性,实现了更高的有效性。这一案例突显出单纯依靠信度不足以判断评分质量,只有综合考量信度与有效性,才能获得可靠的评分质量评估,指导更优质的数据采集和模型训练策略。
在实际操作中,评分的主观性、多样性和任务复杂性决定了测量指标的具体门槛难以统一制定。类目分布不均衡、评审者背景差异、事件定义模糊等都会对信度与有效性带来影响。因此,建议结合多种指标和方法,通过增减标签数量、改进评分标准、优化工具流程等手段,不断摸索和提升评分体系的整体质量。此外,对于缺乏明确金标准的领域,还应积极引入专家共识、跨池检验等方式强化结果的客观性和可复制性。 总的来说,人类评分因其独特的主观判断特性,始终伴随着测量噪声和不确定性。通过科学严谨地衡量其信度与有效性,数据科学家和研究者能够更深入理解评分数据的内在质量,推动从标注工具到模型训练的整体优化。
随着技术的进步和方法论的发展,基于跨复现信度和混合模型的新型测量框架,必将成为评估和提升人类评分质量的关键利器,助力实现更精准、更可信的人工智能及数据驱动应用。