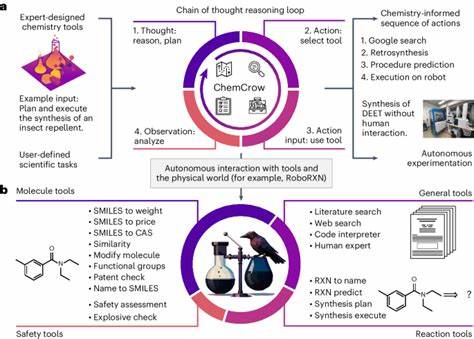
随着人工智能技术的迅速发展,大型语言模型(LLM)在多个领域展现出强大的潜力和广泛的应用场景。特别是在化学领域,LLM凭借其强大的语言处理能力和海量训练数据,开始被用于化学知识解析、反应预测、材料设计等诸多方面。然而,尽管这些模型的化学能力备受关注,人们对于它们与传统化学专家之间的知识深度与推理能力的比较依然存在诸多疑问。本文围绕大型语言模型的化学知识和推理能力展开深入探讨,剖析它们与人类化学专家的异同,并展望对未来化学教育与科研工作的影响。过去,化学知识的传递和传承依赖于专业化学家的专业训练和长期积累,涵盖从分子结构分析到复杂反应机理的深度理解。与此同时,LLM通过对海量化学文献、教材和数据的学习,形成了一种基于文本的表征体系,能够在一定程度上模仿人类化学思维提供答案并进行推理。
近期,研究人员建立了名为ChemBench的评估框架,涵盖了约2700个化学问题,覆盖了大学本科及研究生课程中的各类化学主题和技能要求。通过这一框架,对多个领先的大型语言模型与19位不同领域的化学专家进行了综合评估。结果显示,顶尖的语言模型在整体表现上甚至超越了参与测试的最佳化学专家,在多领域显示出卓越的知识掌握和问题解决能力。这一发现引发了学界对人工智能在化学领域潜力的极大关注,也为药物发现、材料科学和化学研究带来了全新思路。然而,值得注意的是,当前的模型在处理某些基础但关键的问题时仍存在困难,尤其是在需深入推理和结构分析的任务上表现不佳。例如,涉及分子对称性和核磁共振信号预测的高级分析题目,模型的准确率明显低于人类专家。
此外,LLM经常表现出过度自信的现象,在错误的答案上依然给出较高的置信度评分,这在安全性和可靠性要求极高的化学应用中存在潜在风险。针对化学偏好判断等开放式任务,模型的表现更是不尽人意,难以与专业人士的直觉和经验相匹配。深入分析还表明,虽然后期通过外部工具如文献检索和数据库查询可以部分弥补模型的知识盲点,但由于某些化学信息需要高度专业的数据库支持,单靠通用文献搜索难以提供完全准确的答案。因此,将模型与专门的化学数据库深度融合可能是提升性能的关键路径。基于化学领域的这些发现,也对现有的教学和考核体系提出了挑战。传统以死记硬背和单一题型为主的考试正在被证明难以有效区分人类和机器的能力,推动教育者从知识灌输转向培养学生批判性思维和复杂推理能力,这对未来化学人才的培养至关重要。
同时,ChemBench的问答设计理念也反映出化学问题的多样性和综合性,涵盖知识记忆、演算推理、直觉判断等多个维度,为评估机器与人类能力提供了更加细致和科学的标准。展望未来,基于大型语言模型和自动评估框架的化学辅助系统将在科研和工业应用中扮演重要角色。它们不仅可以作为化学家的“智能助手”,帮助快速获取文献内容、建议实验方案,还能通过不断迭代优化,提升科研效率和创新能力。然而,要实现这一目标,模型在理解复杂化学结构、准确推理以及合理判断不确定性方面仍需重大突破。为此,模型设计者、化学专家和教育者需要紧密合作,不断优化训练数据的质量和多样性,开发更具解释性和安全性的模型架构,同时强化人机交互方式,使模型的建议更具实用价值和可信度。此外,随着人工智能在化学中的深入应用,伦理和安全问题不容忽视。
例如,技术可能被滥用于设计有害物质,普通用户依赖模型的错误信息导致安全事故等,因此必须建立完善的监管和风险防控机制。结语大型语言模型在化学知识和推理方面展示了前所未有的能力,甚至能够超越部分专业化学家的表现。这一进展不仅为化学科研和教育带来深远影响,也为智能化科学研究奠定坚实基础。尽管现阶段仍存在不少不足和挑战,但随着技术的发展与完善,未来AI与人类专家的协同合作将极大推动化学科学的创新和应用,开启化学研究的新纪元。