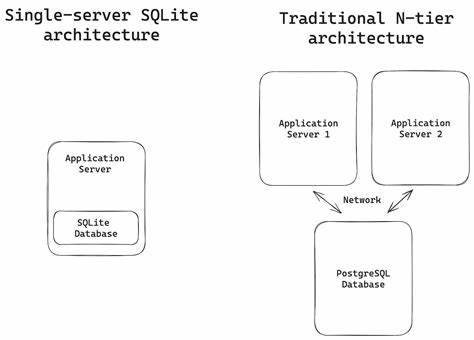
在现代应用架构中,轻量级嵌入式数据库与分布式高可用系统之间的矛盾日益明显。传统的 SQLite 因为安装简单、性能优秀和零运维的特性在许多场景获得青睐,但当业务需要跨节点复制、高可用性和多语言远程访问时,单机 SQLite 显得力不从心。HA SQLite Cluster 应运而生,它通过将 SQLite 与 NATS JetStream 结合,提供一种既保留 SQLite 简洁性的同时支持分布式复制与高可用特性的解决方案。本文从架构、安装、使用场景、复制机制、冲突解决、性能与运维等维度,系统讲解 HA SQLite Cluster 的核心能力与实战要点,帮助开发者评估并快速上手这一分布式 SQLite 平台。 HA SQLite Cluster 的核心理念是把 SQLite 保持为本地存储的执行引擎,同时用 NATS JetStream 作为消息总线与持久化层来实现变更复制与快照存储。每个节点内部运行一个或连接到一个 NATS JetStream 服务,所有的数据变更事件会被序列化为 CDC 消息并发布到 JetStream 流中。
JetStream 提供的 at-least-once 投递保证结合 HA 的幂等化设计,使得在网络抖动或节点故障时,复制仍能稳定恢复。架构的另一个关键点是支持多种外部访问协议,包含 HTTP API、gRPC、database/sql go 驱动、JDBC 驱动以及兼容 PostgreSQL 和 MySQL Wire Protocol 的接口,让现有生态可平滑接入而无需大幅改造应用代码。 从安装与部署角度来看,HA SQLite Cluster 提供灵活的选项,既可以以 Docker 容器快速启动单节点或多节点集群,也可以通过 Helm Chart 在 Kubernetes 上进行标准化部署。对于轻量测试场景,直接以内存模式启动能够最快速体验系统行为,而生产环境常见做法是为 NATS 指定持久化存储目录以保存流状态和对象存储快照。部署时建议为每个节点配置单独的 HTTP 和数据库监听端口,同时根据业务需求决定是否启用嵌入式 NATS 或外部托管的 NATS 集群。在 Kubernetes 中借助 Helm 可以便捷地设置副本数、持久卷、服务暴露和资源限额,从而把集群运行在标准的云原生环境里。
使用体验是 HA SQLite Cluster 的另一个亮点。开发者可以通过 HTTP API 直接发送 SQL 与参数化查询,API 支持事务内多语句批量提交,返回结构化的执行结果。对于偏好标准驱动的应用,数据库驱动层已经实现了对 database/sql 的支持,并且提供了 go-ha 驱动来创建本地读写副本,实现对远端 HA 集群的低延迟访问。对于数据库客户端生态的兼容性考虑,HA 还实现了 PostgreSQL 与 MySQL 的 Wire Protocol,允许现有工具与驱动(例如 psql、MySQL 客户端、DBeaver 等)无需修改应用逻辑即可连接并执行 SQL。值得注意的是,SQLite 的语法解析与行为仍然主导执行细节,因此 Postgres 或 MySQL 的某些函数和行为在 HA 集群中并不完全支持,需要在迁移时提前评估兼容性。 复制与一致性是分布式数据库设计的核心挑战之一。
HA SQLite Cluster 的复制采用 leaderless 写入模型,默认允许对任意节点写入,从而提升可用性与写入吞吐,但这也带来潜在的冲突情形。为减少冲突带来的不确定性,系统对所有 DML 操作进行幂等化处理,并采用 Last Writer Wins 的冲突策略。DDL 语句也会被复制,但对 ALTER TABLE 这类操作的处理没有 DDL 创建与删除指令那样简单,建议在变更结构时通过集中化的步骤或固定的 leader 节点来执行以避免复杂冲突。系统提供了 interceptor 插件机制,允许用户通过自定义的 Go 脚本注入冲突解决逻辑或过滤策略,从而将通用的最后写入策略替换为更适合业务语义的合并策略。 变更数据捕获 CDC 是 HA 的复制核心。每次写操作都会生成一个描述性事件,包含变更的表、列名、操作类型、行标识以及新旧值等元数据。
这些事件以 JSON 格式或其他兼容格式发布到 JetStream,对外可以消费或持久存储到 JetStream 的对象存储中。JetStream 的对象存储则承担快照保存的责任,系统支持按需或定时触发数据库快照并将其保存到对象存储,方便节点重建或在新节点上线时快速恢复到最近一致状态。快照结合日志回放能显著缩短节点恢复时间并降低网络复制的负载。 本地副本功能为延迟敏感的场景带来实用价值。HA 提供两类本地副本方案:读写副本的 go-ha 驱动和使用 ha-sync SQLite 扩展创建的本地只读副本。读写副本适用于 Go 生态并且可以在本地内嵌轻量副本来降低远端访问延迟,同时保留与远端集群同步的能力。
只读副本则更通用,任何支持 SQLite 的语言都可以通过 ha-sync 扩展实现本地的数据缓存,用于读取加速与离线查询场景。但需要注意副本的一致性窗口和冲突风险,读写副本在设计上需要谨慎处理写入路由,避免因跨副本并行写入带来的不一致性。 运维层面,HA 提供多种工具来管理复制、快照与状态监控。通过 HTTP API 可以列出所有复制状态、查看单个复制的健康情况、删除复制消费者以及发起快照或下载在线备份。运维人员可以结合这些 API 实现自动化备份策略、故障转移脚本和健康检查探针。JetStream 的流与对象存储策略如保留副本数、消息最大年龄等参数都可配置,用以在不同的部署环境中平衡存储成本与数据恢复能力。
安全性与认证在生产环境中尤为重要。HA 支持为 PostgreSQL 与 MySQL Wire Protocol 配置用户名与密码,同时也支持为 HTTP API 设置访问令牌。嵌入式 NATS 可以配置用户、密码和配置文件,或直接禁用嵌入式 NATS 并连接到外部托管的 NATS 服务以利用更成熟的安全机制与运维能力。启用 TLS 是在公网或不受信任网络中部署时的必需项,应为数据库连接与 NATS 通信配置证书与加密隧道,从而防止数据在传输中被窃取或篡改。 性能优化方面,HA 内部对并发查询进行了连接池与并发限制的配置项,允许通过调整并发查询上限和数据库池大小来匹配机器资源与业务并发模式。写入路径的关键在于 JetStream 的发布延迟与本地 SQLite 的写入性能,合适地调整 JetStream 的副本数与同步策略可以在延迟与耐久度之间做权衡。
对于写密集型负载,建议评估开启异步复制发布的影响以及本地异步队列存储目录的 I/O 能力,避免因异步排队导致不可接受的延迟积累。 在迁移与兼容性方面,将现有 SQLite 工作负载迁移到 HA 集群通常是较为平滑的过程,但需要注意一些边界条件。Tables WITHOUT ROWID 的表在当前复制机制中不被支持,带有 ON CONFLICT REPLACE 的删除行为不会触发复制事件,复杂的 ALTER TABLE 操作在分布式环境下也容易产生不一致。因此在迁移之前,建议先进行模式审查,必要时改写部分表结构以兼容复制机制。对于需要强一致性的业务,有两种常见做法可选:将所有写操作集中路由到同一 leader 节点,或者使用 leader-static 或 leader-addr 等参数显式指定 leader,从而实质上把写操作序列化到单一节点上,换取一致性保证。 备份与恢复能力是分布式数据库的生命线。
HA 提供在线下载整个数据库的备份接口,以及将快照保存到 JetStream 对象存储的能力。定期触发快照并将其导出到远端持久化存储是最佳实践。快照配合变更日志回放可实现定点恢复,支持从最近快照开始仅回放自那之后的 CDC 消息,从而降低恢复时需要重放的日志量。运维团队应结合业务 RTO 与 RPO 要求制定快照频率与保留策略,并定期进行恢复演练以验证备份链路的可靠性。 实际应用场景方面,HA SQLite Cluster 适合嵌入式设备、边缘计算节点、轻量化微服务以及需要简化运维但又希望具备跨节点高可用性的中小型业务系统。低运维成本和兼容 SQLite 的优势使其成为将 SQLite 从单机扩展到多节点的实用选择。
对于要求极高一致性的金融类或强事务隔离的核心业务,仍需要结合系统的写路由策略或选择更强一致性的专用分布式数据库。 总结来看,HA SQLite Cluster 在兼顾 SQLite 简洁性的同时,通过 NATS JetStream 提供可靠的变更分发、快照存储与持久化支持,为轻量级数据库提供了一条通向分布式可用性的路径。其多协议接入、灵活的本地副本方案与可扩展的运维 API 使其在很多场景下成为有价值的选择。关键的注意事项包括评估表结构兼容性、合理配置 JetStream 与快照策略、为冲突管理制定清晰方案以及在部署中确保网络与存储层的可靠性。通过这些实践,工程团队可以在保持 SQLite 开发效率的同时,享受分布式系统带来的高可用性与弹性。 如果计划试用,可以从快速的 Docker 启动或在 Kubernetes 中通过 Helm Chart 部署开始,优先在开发与预发布环境验证复制、快照与恢复流程,并根据业务负载调整 JetStream 配置与本地副本策略。
随着对系统特性的熟悉,可以进一步利用 interceptor 接口实现更贴合业务的冲突处理逻辑,从而将 HA SQLite Cluster 打造成既轻量又可靠的分布式数据层解决方案。 。